3.Краткая интерлюдия: О Связях и Абстракции

Позвольте нам, дорогой читатель, сделать небольшое отступление от темы абстракций. Мы довольно много говорили об абстракциях. Например, шаблон репозитория-это абстракция над складом. Но что делает хорошую абстракцию? Чего мы хотим от абстракций? И как они связаны с тестированием?
Код для этой главы находится в ветке chapter_03_abstractions on GitHub: |
Ключевая тема этой книги, скрытая среди причудливых хитроплетений, заключается в том, что мы можем использовать простые абстракции, чтобы скрыть беспорядочные детали. Когда мы пишем код для удовольствия или в ката,[1] мы можем свободно упражняться с идеями, вычленяя сущности и агрессивно рефакторингуя. Однако, в крупномасштабной системе, наши решения становимся ограниченными, другими решениями, принятыми в других частях системы.
Когда мы не можем изменить компонент A из опасения сломать компонент B, мы говорим, что компоненты стали связанными или сцепленными (coupled). Локальное сцепление — это хорошо: это признак того, что наш код работает дружно "всем коллективом", каждый компонент поддерживает другие, все они подходят друг к другу, как колёсики в часах. Говоря на жаргоне будет сказано как то так: это работает, когда существуют жесткие связи между связанными элементами.
Вот в глобальном масштабе жёстка связанность (сцепление) — это неприятность: Увеличивается риск и стоимость внесения изменений нашего кода, иногда до такой степени, что мы чувствуем себя неспособными внести какие-либо изменения вообще. Это проблема на рисунке Шара грязи может быть описана так: по мере роста приложения, в случае если мы не можем предотвратить жесткую связанность между элементами, которые не связаны друг с другом, эта взаимосвязь будет прогрессировать сверхлинейно, до тех пор пока мы больше не сможем эффективно вносить изменения в наши системы.
Мы можем уменьшить степень сцепления внутри системы ([coupling_illustration1]) абстрагируясь от деталей ([coupling_illustration2]).
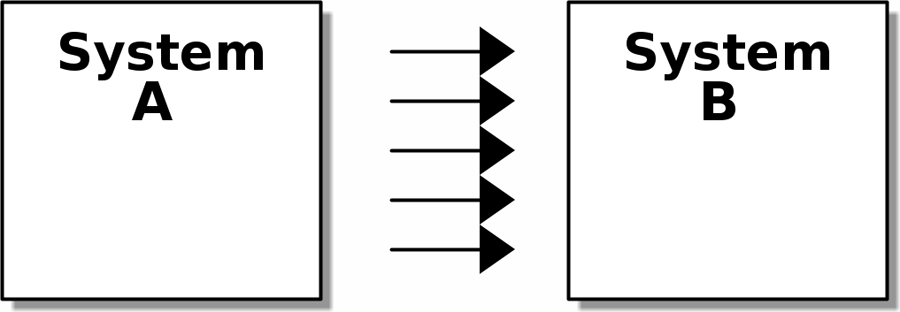

На обеих диаграммах у нас есть пара подсистем, одна из которых зависит от другой.В [coupling_illustration1] между ними существует высокая степень связаности; количество стрелок указывает на множество видов зависимостей между ними. Если нам нужно изменить систему B, есть большая вероятность, что это изменение отразится на системе A.
Однако в [coupling_illustration2] мы уменьшили степень связаности, вставив новую, более простую абстракцию. Поскольку она проще, система А имеет меньше видов зависимостей от абстракции. Абстракция служит для защиты нас от изменений, скрывая сложные детали того, что делает система B - мы можем изменить стрелки справа, не меняя стрелки слева.
Абстрагирование от Состояния Улучшает Тестируемость
Давайте рассмотрим пример. Представьте, что мы хотим написать код для синхронизации двух файловых каталогов, которые назовем source и destination:
Если файл существует в источнике, но не в месте назначения, скопируйте его.
Если файл существует в источнике, но имеет другое имя, отличное от имеющегося в папке назначения, переименуйте его в соответствующее.
Если файл существует в папке назначения, но отсутствует в источнике, удалите его.
Первое и третье требования достаточно просты: мы можем просто сравнить два списка путей. Но, вот, со вторым сложнее. Чтобы выявить необходимость переименования, нам придется проверить содержимое файлов. Для этого мы можем использовать функцию хеширования, такую как MD5 или SHA-1. Код для генерации хэша SHA-1 из файла достаточно прост:
BLOCKSIZE = 65536
def hash_file(path):
hasher = hashlib.sha1()
with path.open("rb") as file:
buf = file.read(BLOCKSIZE)
while buf:
hasher.update(buf)
buf = file.read(BLOCKSIZE)
return hasher.hexdigest()
Теперь нам нужно чуть дописать, часть принятия решения "что делать" — Бизнес-логику, если хотите.
Когда нам нужно решить проблему основываясь на первичных принципах, мы обычно пытаемся написать простую реализацию, а затем заняться рефакторингом в сторону лучшего дизайна. Мы будем использовать этот подход на протяжении всей книги, потому что именно так мы пишем код в реальном мире: начните с решения самой маленькой части проблемы, а затем итеративно делайте решение более продвинутым и лучше разработанным.
Наш первый подход выглядит примерно так:
import hashlib
import os
import shutil
from pathlib import Path
def sync(source, dest):
# Пройдите по исходной папке и создайте список имен файлов и их хэшей
source_hashes = {}
for folder, _, files in os.walk(source):
for fn in files:
source_hashes[hash_file(Path(folder) / fn)] = fn
seen = set() # Следите за файлами, которые мы нашли в целевой папке
# Пройдитесь по целевой папке и получите имена файлов и их хэши
for folder, _, files in os.walk(dest):
for fn in files:
dest_path = Path(folder) / fn
dest_hash = hash_file(dest_path)
seen.add(dest_hash)
# если в целевой папке есть файл, которого нет в исходной,
# удалите его
if dest_hash not in source_hashes:
dest_path.remove()
# если в target есть файл, который имеет другой путь в source,
# переместите его на правильный путь
elif dest_hash in source_hashes and fn != source_hashes[dest_hash]:
shutil.move(dest_path, Path(folder) / source_hashes[dest_hash])
# для каждого файла, который появляется в исходной папке,
# но не в целевой, скопируйте его в целевую
for src_hash, fn in source_hashes.items():
if src_hash not in seen:
shutil.copy(Path(source) / fn, Path(dest) / fn)
Фантастика! У нас есть какой-то код, и он выглядит нормально, но прежде чем мы запустим его на жестком диске, может быть, нам стоит его протестировать. Как мы будем тестировать такие штуковины?
def test_when_a_file_exists_in_the_source_but_not_the_destination():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "Я очень полезный файл"
(Path(source) / 'my-file').write_text(content)
sync(source, dest)
expected_path = Path(dest) / 'my-file'
assert expected_path.exists()
assert expected_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
def test_when_a_file_has_been_renamed_in_the_source():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "Я файл, который был переименован"
source_path = Path(source) / 'source-filename'
old_dest_path = Path(dest) / 'dest-filename'
expected_dest_path = Path(dest) / 'source-filename'
source_path.write_text(content)
old_dest_path.write_text(content)
sync(source, dest)
assert old_dest_path.exists() is False
assert expected_dest_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
Строго говоря, тут многовато установок для двух простых случаев! Проблема в том, что логика нашей предметной области «выяснение разницы между двумя каталогами» тесно связана с I/O кодом. Мы не можем запустить наш алгоритм поиска различий без вызова модулей pathlib, shutil и hashlib.
Только вот беда в том, что даже с нашими текущими требованиями мы не написали достаточно тестов: текущая реализация имеет несколько ошибок (например, shutil.move() неверен). Чтобы получить достойное покрытие и выявить эти ошибки, нужно написать больше тестов, но если все они будут такими же громоздкими, как предыдущие, это быстро станет очень геморно.
Вдобавок наш код не очень расширяемый. Представьте, что вы пытаетесь реализовать флаг --dry-run, который заставляет наш код просто распечатать то, что он собирается делать, а не выполнять это на самом деле. А что, если мы хотим синхронизироваться с удаленным сервером или с облачным хранилищем?
Наш высокоуровневый код связан с низкоуровневыми деталями, и это усложняет жизнь. По мере усложнения рассматриваемых сценариев наши тесты будут становиться все более громоздкими. Мы определенно можем провести рефакторинг этих тестов (например, некоторая очистка может быть перенесена в фикстуры pytest), но пока мы выполняем операции с файловой системой, они будут медленными, их будет трудно читать и писать.
Выбор правильной Абстракции(-й)
Что мы можем сделать, чтобы переписать наш код и сделать его более тестируемым?
Во-первых, нам нужно подумать о том, что нужно нашему коду от файловой системы. Разбирая код, мы видим три различных момента. Воспримем их как три различных обязанности, которые выполняет код:
Мы опрашиваем файловую систему с помощью
os.walkи определяем хэши для ряда путей. Это похоже как для исходного, так и конечного случая.Мы решаем, является ли файл новым, переименованным или лишним.
Мы копируем, перемещаем или удаляем файлы в соответствии с источником.
Помните, что мы хотим найти упрощающие абстракции для каждой из этих обязанностей. Это позволит нам скрыть беспорядочные детали, чтобы мы могли сосредоточиться на интересующей нас логике.[2]
В этой главе мы отрефакторим слегка корявый код в более проверяемую структуру, определяя отдельные задачи, которые необходимо выполнить, и предоставляя каждую задачу четко определенному субъекту, аналогично пример duckduckgo. |
Для шагов 1 и 2 мы уже интуитивно начали использовать абстракцию, словарь хэшей для путей. Возможно, вы уже думали: «Почему бы не создать словарь для целевой папки, а также для источника, а затем мы просто сравним два словаря?» Это похоже на хороший способ абстрагироваться от текущего состояния файловой системы:
source_files = {'hash1': 'path1', 'hash2': 'path2'}
dest_files = {'hash1': 'path1', 'hash2': 'pathX'}А как насчет перехода от пункта 2 к пункту 3? Как мы можем абстрагироваться от фактического взаимодействия файловой системы перемещения/копирования/удаления?
Мы применим здесь трюк, который будем применять позже в этой книге достаточно широко. Мы собираемся отделить то, что мы хотим сделать, от того, как это сделать. Мы собираемся сделать так, чтобы наша программа выводила список команд, которые выглядят следующим образом:
("COPY", "sourcepath", "destpath"),
("MOVE", "old", "new"),Теперь мы могли бы написать тесты, которые просто используют два дикта файловой системы в качестве входных данных, и мы ожидали бы списки кортежей строк, представляющих действия в качестве выходных данных.
Вместо того чтобы сказать: "Учитывая фактическую файловую систему при запуске своей функции, проверить, какие действия произошли", мы говорим: "Учитывая абстрацию файловой системы, какое абстрактное действие файловой системы произойдет?"
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
expected_actions = [('COPY', '/src/fn1', '/dst/fn1')]
...
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
expected_actions == [('MOVE', '/dst/fn2', '/dst/fn1')]
...
Реализация Выбранных Нами Абстракций
Это все очень хорошо, но как нам на самом деле написать эти новые тесты и как изменить нашу реализацию, чтобы все это работало?
Наша цель состоит в том, чтобы изолировать умную часть нашей системы и иметь возможность тщательно протестировать её без необходимости создавать реальную файловую систему. Мы создадим "ядро" кода, которое не имеет зависимостей от внешнего состояния, а затем посмотрим, как оно реагирует, когда мы даем ему входные данные из внешнего мира (такой подход был охарактеризован Гэри Бернхардтом как Functional Core, Imperative Shell, или FCIS).
Давайте начнем с разделения кода, чтобы отделить части с состоянием от логики.
И наша функция верхнего уровня не будет содержать почти никакой логики вообще; это просто обязательная серия шагов: собрать входные данные, вызвать нашу логику, применить результаты:
def sync(source, dest):
# imperative shell Шаг 1, собрать входные данные
source_hashes = read_paths_and_hashes(source) # dest_hashes = read_paths_and_hashes(dest) #
# Шаг 2: вызов функционального ядра
actions = determine_actions(source_hashes, dest_hashes, source, dest) #
dest_hashes = read_paths_and_hashes(dest) #
# Шаг 2: вызов функционального ядра
actions = determine_actions(source_hashes, dest_hashes, source, dest) # # imperative shell Шаг 3, применить результаты
for action, *paths in actions:
if action == 'copy':
shutil.copyfile(*paths)
if action == 'move':
shutil.move(*paths)
if action == 'delete':
os.remove(paths[0])
# imperative shell Шаг 3, применить результаты
for action, *paths in actions:
if action == 'copy':
shutil.copyfile(*paths)
if action == 'move':
shutil.move(*paths)
if action == 'delete':
os.remove(paths[0])
Первая функция, которую мы учитываем, read_paths_and_hashes(), которая изолирует часть ввода-вывода нашего приложения. | |
| Именно здесь мы вырежем функциональное ядро, бизнес-логику. |
Код для создания словаря путей и хешей теперь написать тривиально просто:
def read_paths_and_hashes(root):
hashes = {}
for folder, _, files in os.walk(root):
for fn in files:
hashes[hash_file(Path(folder) / fn)] = fn
return hashes
Функция define_actions() будет ядром нашей бизнес-логики, которая выясняет: «Учитывая эти два набора хэшей и имен файлов, что мы должны копировать/перемещать/удалять?». Она принимает простые структуры данных и возвращает простые структуры данных:
def determine_actions(src_hashes, dst_hashes, src_folder, dst_folder):
for sha, filename in src_hashes.items():
if sha not in dst_hashes:
sourcepath = Path(src_folder) / filename
destpath = Path(dst_folder) / filename
yield 'copy', sourcepath, destpath
elif dst_hashes[sha] != filename:
olddestpath = Path(dst_folder) / dst_hashes[sha]
newdestpath = Path(dst_folder) / filename
yield 'move', olddestpath, newdestpath
for sha, filename in dst_hashes.items():
if sha not in src_hashes:
yield 'delete', dst_folder / filename
Теперь наши тесты действуют непосредственно на функцию determine_actions():
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('copy', Path('/src/fn1'), Path('/dst/fn1'))]
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('move', Path('/dst/fn2'), Path('/dst/fn1'))]
Поскольку мы отделили логику нашей программы — код для идентификации изменений — от низкоуровневых деталей ввода-вывода, мы можем легко протестировать ядро нашего кода.
При таком подходе мы перешли от тестирования нашей основной функции точки входа sync() к тестированию функции более низкого уровня determine_actions(). Вы можете решить, что это нормально, потому что sync() теперь выполняется так просто. Или вы можете решить провести несколько интеграционных/приемочных тестов, чтобы проверить эту sync(). Но есть еще один вариант, который заключается в изменении функции sync(), чтобы её можно было тестировать модульно и тестировать от начала до конца; это подход, который Боб называет edge-to-edge testing.
Тестирование Edge to Edge с Fakes и Dependency Injection
Когда мы начинаем писать новую систему, мы часто сначала фокусируемся на основной логике, управляя ею с помощью прямых модульных тестов. Однако в какой-то момент мы хотим протестировать совместное использование большой части системы.
Мы бы могли вернуться к нашим сквозным тестам, но они все еще так же сложны в написании и обслуживании, как и раньше. Вместо этого мы часто пишем тесты, которые вызывают целую систему вместе, но подделывают ввод-вывод, своего рода edge to edge:
def sync(reader, filesystem, source_root, dest_root): #
source_hashes = reader(source_root) #
dest_hashes = reader(dest_root)
for sha, filename in src_hashes.items():
if sha not in dest_hashes:
sourcepath = source_root / filename
destpath = dest_root / filename
filesystem.copy(destpath, sourcepath) # elif dest_hashes[sha] != filename:
olddestpath = dest_root / dest_hashes[sha]
newdestpath = dest_root / filename
filesystem.move(olddestpath, newdestpath)
for sha, filename in dst_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest_root/filename)
elif dest_hashes[sha] != filename:
olddestpath = dest_root / dest_hashes[sha]
newdestpath = dest_root / filename
filesystem.move(olddestpath, newdestpath)
for sha, filename in dst_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest_root/filename)
Наша функция верхнего уровня теперь предоставляет две новые зависимости: reader и filesystem. | |
Мы вызываем reader для создания наших файлов dict. | |
Мы вызываем filesystem, чтобы применить обнаруженные нами изменения. |
| Хотя мы используем инъекцию зависимостей, нет необходимости определять абстрактный базовый класс или какой-либо явный интерфейс. В этой книге мы часто показываем ABC, потому что надеемся, что этот модуль поможет вам понять, что такое абстракция, но в этом нет необходимости. Динамический характер Python означает, что мы всегда можем положиться на утиную типизацию[3]. |
class FakeFileSystem(list): #
def copy(self, src, dest): #
self.append(('COPY', src, dest))
def move(self, src, dest):
self.append(('MOVE', src, dest))
def delete(self, dest):
self.append(('DELETE', dest))
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source = {"sha1": "my-file" }
dest = {}
filesystem = FakeFileSystem()
reader = {"/source": source, "/dest": dest}
sync(reader.pop, filesystem, "/source", "/dest")
assert filesystem == [("COPY", "/source/my-file", "/dest/my-file")]
def test_when_a_file_has_been_renamed_in_the_source():
source = {"sha1": "renamed-file" }
dest = {"sha1": "original-file" }
filesystem = FakeFileSystem()
reader = {"/source": source, "/dest": dest}
sync(reader.pop, filesystem, "/source", "/dest")
assert filesystem == [("MOVE", "/dest/original-file", "/dest/renamed-file")]
Боб обожает использовать списки для создания простых тестовых двойников, даже если это бесит его коллег. Это означает, что мы можем писать тесты вроде assert foo not in database. | |
Каждый метод в нашей FakeFileSystem просто добавляет что-то в список, чтобы мы могли проверить это позже. Это пример spy object. |
Преимущество этого подхода заключается в том, что наши тесты работают с той же функцией, которая используется нашим production кодом. Недостатком является то, что мы должны сделать наши компоненты с отслеживанием состояния явными и передавать их по кругу. Дэвид Хайнемайер Ханссон, создатель Ruby on Rails, как известно, описал это как "вызванное тестом повреждение конструкции."
В любом случае, теперь мы можем работать над исправлением всех ошибок в нашей реализации; Перечисление тестов для всех крайних случаев стало намного проще.
Почему бы просто не запатчить это?
В этот момент вы можете почесать затылок и подумать: "Почему бы просто не использовать mock.patch и не сэкономить свои усилия?"
Мы избегаем использования моков в этой книге и в нашем production коде. Мы не собираемся устраивать ХолиВар по этому поводу, но инстинкт подсказывает, что mocking frameworks, особенно monkeypatching, - это дурнопахнущий код.
Вместо этого мы предпочитаем четко определять обязанности в нашей кодовой базе и разделять эти обязанности на небольшие, сфокусированные объекты, которые легко заменить тестовым дублёром.
Вы можете увидеть пример в [chapter_08_events_and_message_bus], где мы mock.patch()-ем выводим модуль отправки электронной почты, но в конечном итоге заменяем его явным небольшим кодом внедрения зависимостей в [chapter_13_dependency_injection]. |
У нас есть три тесно связанных причины нашего предпочтения:
Исправление зависимости, которую вы используете, позволяет модульно протестировать код, но это никак не улучшает дизайн. Использование
mock.patchне позволит вашему коду работать с флагом--dry-runи не поможет вам работать с FTP-сервером. Для этого вам нужно будет ввести абстракции.Тесты, которые используют mocks стремятся быть более связанными с деталями реализации кодовой базы. Это потому, что имитационные тесты проверяют взаимодействие между объектами: вызывали ли мы
shutil.copyс правильными аргументами? По нашему опыту, эта связь между кодом и тестом стремится сделать тесты более хрупкими.Чрезмерное использование моков приводит к созданию сложных наборов тестов, которые не могут объяснить код.
| Проектирование для тестируемости на самом деле означает проектирование для расширяемости. Мы обмениваем немного большую сложность на более чистый дизайн, который допускает новые варианты использования. |
Мы рассматриваем TDD в первую очередь как практику проектирования, а затем как практику тестирования. Тесты выполняют функцию хранения наших вариантов проектирования и служат для объяснения системы, когда мы возвращаемся к коду после долгого отсутствия.
Тесты, использующие слишком много mocks, перегружаются установочным кодом, который скрывает интересующую нас историю.
В своем выступлении Стив Фриман приводит отличный пример чрезмерно замкнутых тестов. "Test-Driven Development". Вам также следует ознакомиться с этим выступлением PyCon, "Mocking and Patching Pitfalls", от нашего уважаемого технического обозревателя Эда Юнга, который также рассматривает mocking и их альтернативы. И в то время как мы рекомендуем доклады, не пропустите Брэндона Родса, говорящего о "Hoisting Your I/O", который действительно хорошо охватывает проблемы, о которых мы говорим, используя еще один простой пример.
| В этой главе мы потратили много времени, заменяя сквозные тесты модульными. Это не значит, что мы считаем, что вы никогда не должны использовать тесты E2E! В этой книге мы показываем методы, которые помогут вам составить достойную пирамиду тестов с максимально возможным количеством модульных тестов и с минимальным количеством тестов E2E, необходимых для уверенности. Прочтите [types_of_test_rules_of_thumb] для получения более подробной информации. |
Подведение итогов
Мы будем видеть эту идею в книге снова и снова: мы можем упростить тестирование и обслуживание наших систем, упростив интерфейс между нашей бизнес-логикой и беспорядочным вводом-выводом. Найти правильную абстракцию сложно, но вот несколько эвристик и вопросов, которые нужно задать себе:
Могу ли я выбрать знакомую структуру данных Python для представления состояния беспорядочной системы, а затем попытаться представить себе единственную функцию, которая может вернуть это состояние?
Где я могу провести границу между моими системами, где я смогу использовать шов чтобы вставить эту абстракцию?
Что такое разумный способ разделения объектов на компоненты с различными обязанностями? Какие неявные понятия я могу сделать явными?
Что же такое зависимость, и каковы основные бизнес-логики?
Практика делает его менее несовершенным! А теперь вернемся к нашим баранам нашему обычному программированию…



Комментарии
Отправить комментарий