2.Repository Pattern
Пришло время выполнить обещание использовать принцип инверсии зависимостей как способ отделить основную логику от инфраструктурных проблем.
Представляем вам шаблон Repository, он упрощает абстракцию над хранилищем данных, позволяющую нам отделить слой модели от слоя данных. Давайте приведем конкретный пример того, как эта упрощающая абстракция делает нашу систему более тестируемой, скрывая сложности базы данных.
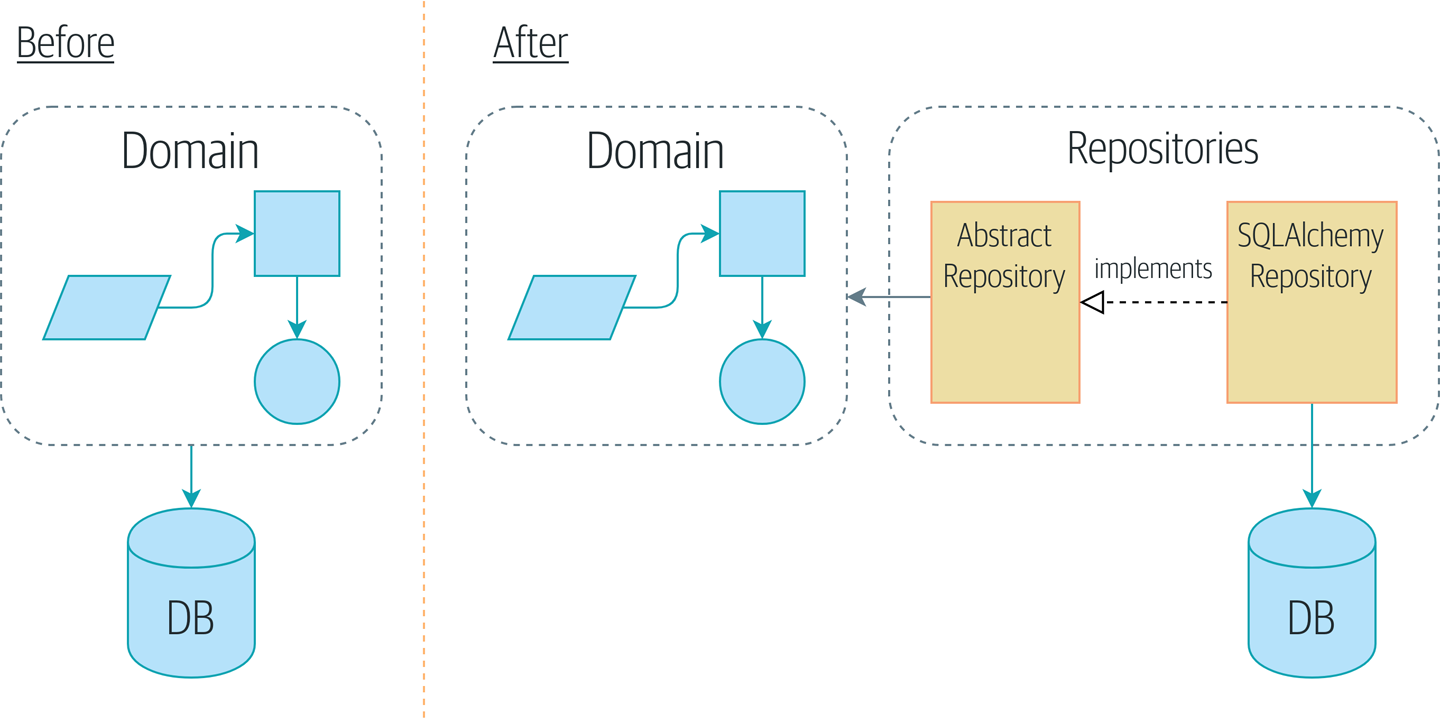
Картина [maps_chapter_02] илюстрирует то, что мы собираемся построить: объект Repository, который находится между нашей моделью предметной области и базой данных.
Код для этой главы находится в chapter_02_repository branch on GitHub. |
Persisting Our Domain Model
В [chapter_01_domain_model] мы построили простую модель домена, которая может распределять заказы по партиям запасов. Мы относительно легко написали тесты для такого кода, потому что нет никаких зависимостей или инфраструктуры для настройки. Если бы нужно было запустить базу данных или API и создать тестовые данные, тесты было бы сложнее писать и поддерживать.
К сожалению, в какой-то момент нам придется передать эту идеальную маленькую модель в руки пользователей и бороться с реальным миром электронных таблиц, веб-браузеров и условий гонки. В следующих нескольких главах мы рассмотрим, как связать идеализированную модель предметной области с внешним состоянием.
В надежде на то, что мы будем работать гибко, наш основной приоритет — как можно быстрее получить минимально жизнеспособный продукт. В нашем случае это будет веб-API. В реальном проекте вы можете сразу погрузиться в несколько сквозных (end-to-end) тестов и начать подключать веб-фреймворк, тестируя функционал извне.
Но мы знаем, что, несмотря ни на что, нам понадобится какая-то форма постоянного хранения. Поскольку это учебник, мы можем позволить себе немного больше развития снизу вверх и начать думать о хранении и базах данных.
Псевдокод: Что делать то будем?
Когда мы создаём наш первый endpoint API, подразумеваем, что у нас будет некоторый код, который выглядит более или менее похожим на этот.
@flask.route.gubbins
def allocate_endpoint():
# извлечь строку заказа из запроса
line = OrderLine(request.params, ...)
# загрузить все партии из БД
batches = ...
# передать в domain service
allocate(line, batches)
# затем сохраните выделеные позици обратно в базу данных
return 201
| Мы использовали Flask, потому что он достаточно простой, но вам не нужно быть с Flask на "ты", чтобы понять эту книгу. На самом деле, наша задача объяснить, как сделать выбор фреймворка незначительной деталью. |
Нам понадобится способ извлечения пакетной информации из базы данных и создания из нее экземпляров объектов модели домена, а также способ сохранения их обратно в базу данных.
Какого…? Ух-х-х, «gubbins» - это британское слово, означающее «фигня». Вы можете просто забить на это. Это’ж псевдокод, понятно?
Применение DIP для доступа к данным
Как уже упоминалось в введение, многоуровневая архитектура — это общий подход к структурированию системы, которая имеет пользовательский интерфейс, некоторую логику и базу данных (см. [layered_architecture2]).
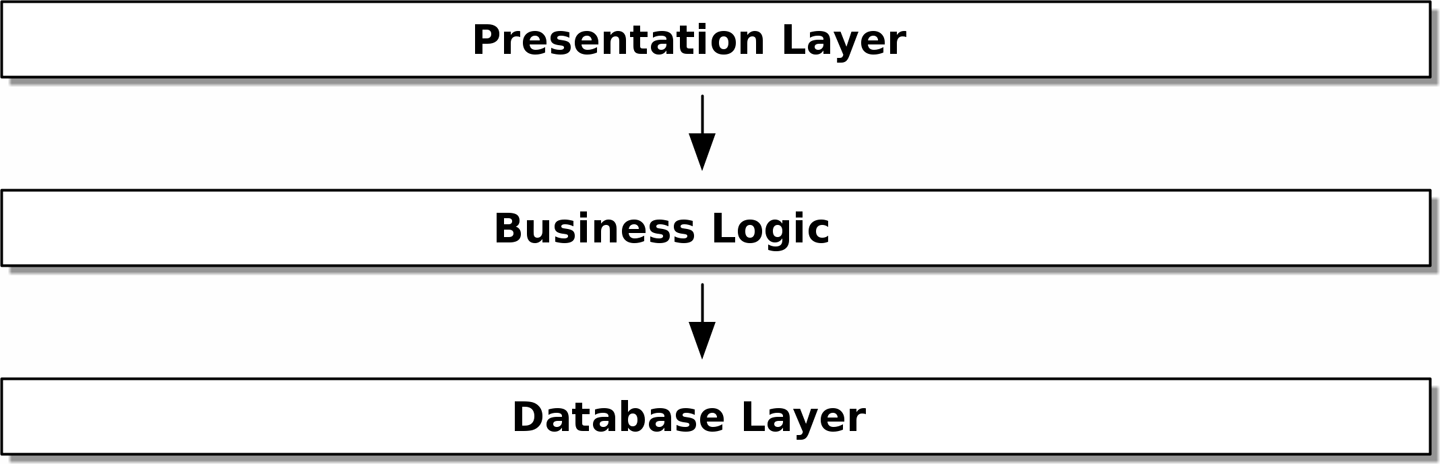
Структура Django Model-View-Template тесно связана, как и Model-View-Controller (MVC). В любом случае цель состоит в том, чтобы слои были разделены (что хорошо), и чтобы каждый слой зависел только от того, который находится под ним.
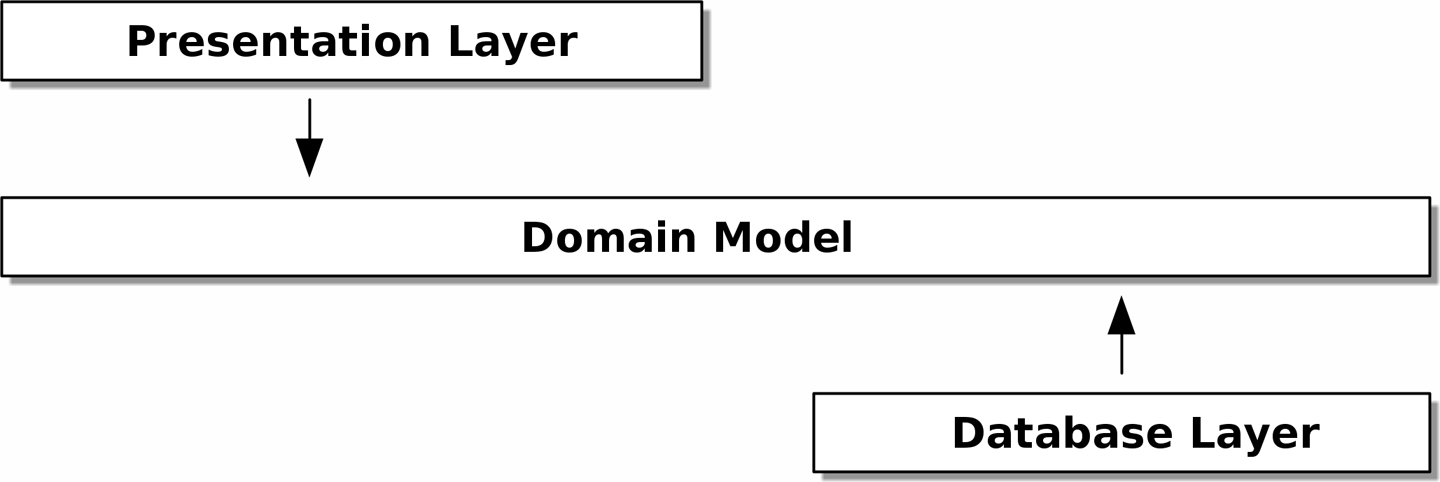
Надо, чтобы в нашей модели предметной области не было никаких зависимостей .[1] Не надо, чтобы проблемы с инфраструктурой проникли в нашу модель предметной области и замедлили наши модульные тесты или нашу способность вносить изменения.
Вместо этого, как обсуждалось во введении, мы будем думать, что наша модель находится "inside (внутри)", и зависимости текут внутрь неё; это то, что умные люди иногда называют onion (луковая) architecture (см. [onion_architecture]).
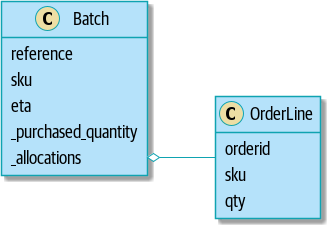
Напоминание: Наша модель
Давайте вспомним нашу модель предметной области (см. [model_diagram_reminder]): Распределение - это концепция связывания OrderLine с Batch. Мы сохраняем выделенные позиици как коллекцию в нашем объекте Batch.
Давайте посмотрим, как мы можем перенести это в реляционную базу данных.
"Нормальный" способ это ORM: Модель зависит от ORM
В наши дни маловероятно, что члены вашей команды вручную создают свои собственные SQL-запросы. Вместо этого вы почти наверняка используете какой-то фреймворк для генерации строк SQL на основе ваших объектов модели.
Эти структуры называются объектно-реляционными картографами object-relational mappers (ОРМ), поскольку они существуют для преодоления концептуального разрыва между миром объектов и моделирования предметной области и миром баз данных и реляционной алгебры.
Самая важная вещь, которую дает нам ORM, - это игнорирование сохраняемости persistence ignorance: идея в том, что наша доменная модель не должна ничего знать о том, как данные загружаются или сохраняются. Это помогает сохранить наш домен чистым от прямых зависимостей конкретных технологий баз данных.[3]
Но если вы будете следовать типичному учебнику SQLAlchemy, то в итоге получите что-то вроде этого:
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...
Вам не нужно разбираться в SQLAlchemy, чтобы увидеть, что наша изначальная модель теперь полна зависимостей от ORM и к тому же начинает выглядеть чертовски уродливо. Можно ли сказать, что эта модель игнорирует базу данных? Как это можно отделить от проблем с хранением, когда свойства нашей модели напрямую связаны со столбцами базы данных?
Инвертирование зависимости: ORM зависит от модели
К счастью, это не единственный способ использовать SQLAlchemy. Альтернативой является определение вашей схемы отдельно и определение явного mapper-а для преобразования между схемой и нашей моделью предметной области, что SQLAlchemy называет classical mapping:
from sqlalchemy.orm import mapper, relationship
import model # metadata = MetaData()
order_lines = Table( #
metadata = MetaData()
order_lines = Table( # 'order_lines', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('sku', String(255)),
Column('qty', Integer, nullable=False),
Column('orderid', String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) #
'order_lines', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('sku', String(255)),
Column('qty', Integer, nullable=False),
Column('orderid', String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) #
| ORM импортирует (или "зависит от" или "знает о") модель предметной области, а не наоборот. | |
| Мы определяем таблицы и столбцы нашей базы данных с помощью абстракций SQLAlchemy.[4] | |
Когда мы вызываем функцию mapper, SQLAlchemy творит чудеса, связывая классы нашей модели предметной области с различными таблицами, которые мы определили. |
Конечным результатом будет то, что, если мы вызовем start_mappers, мы сможем легко загружать и сохранять экземпляры модели домена из базы данных и в нее. Но если мы никогда не вызываем эту функцию, наши классы доменных моделей остаются в блаженном неведении о базе данных.
Это дает нам все преимущества SQLAlchemy, включая возможность использовать alembic для миграций и возможность прозрачного запроса с использованием наших классов домена, как мы увидим.
Когда вы впервые пытаетесь создать свою конфигурацию ORM, может быть полезно написать для неё тесты, как в следующем примере:
def test_orderline_mapper_can_load_lines(session): #
session.execute(
'INSERT INTO order_lines (orderid, sku, qty) VALUES '
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [("order1", "DECORATIVE-WIDGET", 12)]
Если вы не использовали pytest, то аргумент session для этого теста нуждается в объяснении. Смысл такой: Вам не нужно беспокоиться о деталях pytest или его фикстурах в целях этой книги, но главная мысль состоит в том, что вы можете определить общие зависимости для ваших тестов в виде "fixtures", и pytest передаст их в тесты, которые нуждаются в них, приняв их в качестве аргументов функций. В данном случае это сеанс session базы данных SQLAlchemy. |
Вероятно, вам не стоит хранить эти тесты. Как вы вскоре увидите, после того, как поближе познакомитесь с инверсией зависимости ORM и модели предметной области, это всего лишь небольшой дополнительный шаг для реализации другой абстракции, называемой шаблоном репозитория, для которого будет легче писать тесты, и он предоставит простой интерфейс для, скажем так — фейка, позже в тестах.
Но мы уже достигли нашей цели инвертировать традиционную зависимость: модель предметной области остается «чистой» и свободной от инфраструктурных проблем. Мы могли бы выбросить SQLAlchemy и использовать другую ORM или совершенно другую систему сохранения, и модель предметной области вообще не нуждалась бы в изменении.
В зависимости от того, что вы делаете в своей модели предметной области, и особенно если вы отходите далеко от парадигмы объектно-ориентированного программирования, вам может оказаться все труднее заставить ORM обеспечить точное поведение, которое вам нужно, и вам может потребоваться изменить модель предметной области. [5] Как это часто бывает с архитектурными решениями, вам нужно будет найти компромисс. Как говорит дзэн Python: «Практичность лучше чистоты!»
На данный момент, однако, наш endpoint API может выглядеть примерно так, и мы могли бы заставить её работать просто отлично:
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
# извлечение строки заказа из запроса
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
# загрузите все пакеты из БД
batches = session.query(Batch).all()
# call our domain service
allocate(line, batches)
# сохраните распределения обратно в базу данных
session.commit()
return 201
Знакомство с шаблоном репозитория
Шаблон Repository — это абстракция над постоянным хранилищем. Он скрывает скучные детали доступа к данным, делая вид, что все наши данные находятся в памяти.
Если бы у нас была бесконечная память в наших ноутбуках, у нас не было бы необходимости в неуклюжих базах данных. Вместо этого мы могли просто использовать наши объекты, когда нам заблагорассудится. Как это будет выглядеть?
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)
Несмотря на то, что наши объекты находятся в памяти, нам нужно поместить их где-нибудь, чтобы снова найти их. Наши данные в памяти позволят нам добавлять новые объекты, как список или множество. Поскольку объекты находятся в памяти, нам никогда не нужно вызывать метод .save (); мы просто получаем объект, который нам нужен, и модифицируем его в памяти.
The Repository in the Abstract
В простейшем репозитории всего два метода: add () для добавления нового элемента в репозиторий и get() для возврата ранее добавленного элемента.[6]
Мы твердо придерживаемся использования этих методов для доступа к данным в нашем домене и на уровне сервиса. Эта добровольная простота не позволяет нам связать нашу модель предметной области с базой данных.
Вот как будет выглядеть абстрактный базовый класс (ABC) для нашего репозитория:
class AbstractRepository(abc.ABC):
@abc.abstractmethod #
def add(self, batch: model.Batch):
raise NotImplementedError #
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError
Python tip: @abc.abstractmethod — это одна из немногих вещей, которая заставляет ABCs действительно "работать" в Python. Python не позволит вам создать экземпляр класса, который не реализует все "абстрактные методы", определенные в его родительском классе.[7] | |
raise NotImplementedError — это хорошо, но это не обязательно и не достаточно. На самом деле, ваши абстрактные методы могут иметь реальное поведение, которое подклассы могут вызвать, если вы действительно хотите. |
Что такое компромисс?
Знаете, говорят, что экономисты знают всё о цене и ничего о ценности? Программисты же, знают всё о преимуществе и ничего о компромисе.
Всякий раз, когда мы представляем архитектурный паттерн в этой книге, мы всегда задаёмся вопроосом: «Что нам ЭТО даст? И во что нам ЭТО обойдётся?»
Обычно, вводя дополнительный уровень абстракции, мы по крайней мере надеемся, что это уменьшит сложность в целом, а в действительности всё это добавляет сложности локальной и имеет свою стоимость с точки зрения необработанного количества перемещений и текущего обслуживания.
Шаблон репозитория, вероятно, является одним из самых простых вариантов в книге, если вы уже идёте по пути DDD и инверсии зависимостей. Что касается нашего кода, на самом деле мы просто меняем абстракцию SQLAlchemy (session.query (Batch)) на другую (batches_repo.get), которую мы разработали.
Нам придется добавлять несколько строк кода в нашем классе репозитория каждый раз, когда мы добавляем новый объект домена, который мы хотим получить, но взамен мы получаем простую абстракцию над нашим уровнем хранения, который мы контролируем. Шаблон репозитория позволит легко вносить фундаментальные изменения в то, как мы храним объекты (см. [appendix_csvs]), и, как мы увидим, его легко подменить для модульных тестов.
Кроме того, шаблон репозитория настолько распространен в мире DDD, что, если вы сотрудничаете с программистами, пришедшими в Python из мира Java и C#, они, скорее всего, узнают его. [repository_pattern_diagram] иллюстрирует этот паттерн.
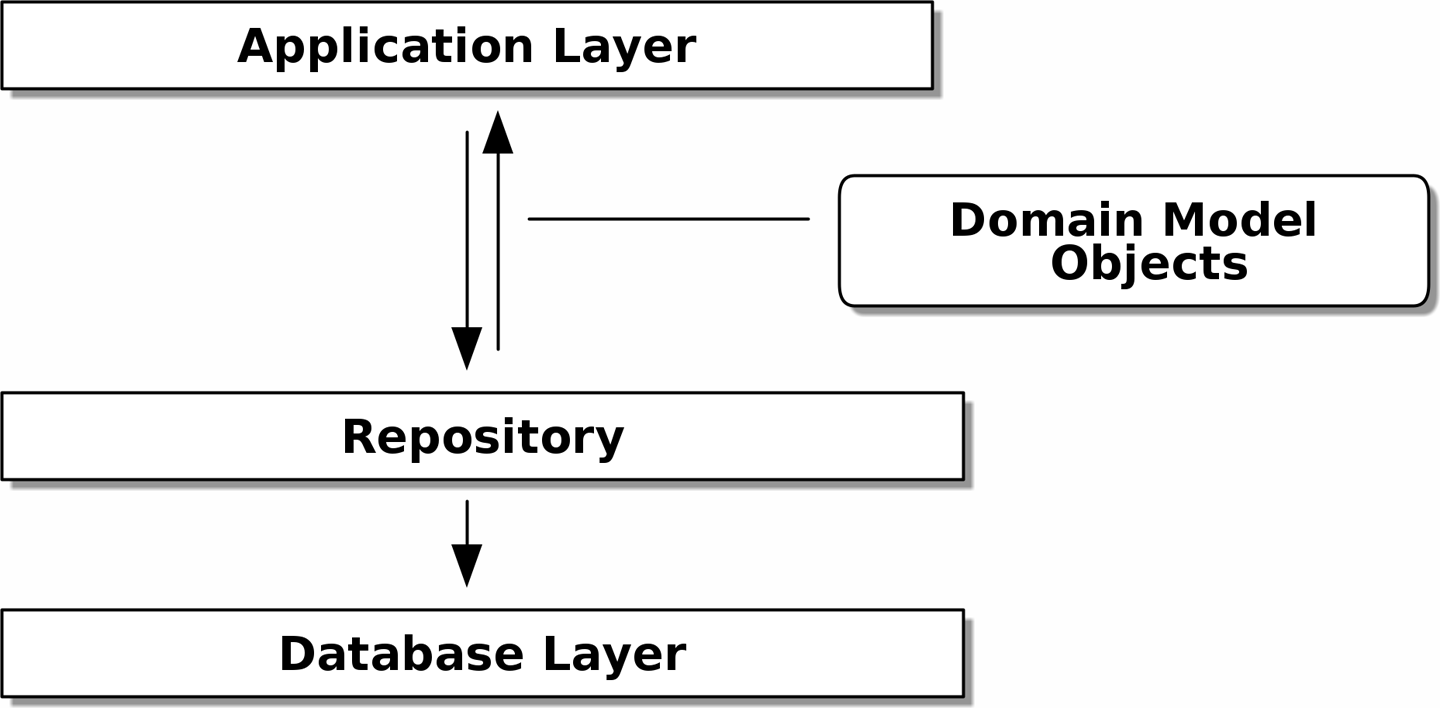
Как всегда, мы начинаем с теста. Это, вероятно, было бы классифицировано как интеграционный тест, поскольку мы проверяем, что наш код (репозиторий) правильно интегрирован с базой данных; следовательно, тесты, как правило, смешивают необработанный SQL с вызовами и ассертами в нашем собственном коде.
| В отличие от предыдущих тестов ORM, эти тесты являются хорошими кандидатами на то, чтобы оставаться частью вашей кодовой базы в долгосрочной перспективе, особенно если какие-либо части вашей модели предметной области означают, что объектно-реляционная карта нетривиальна. |
def test_repository_can_save_a_batch(session):
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch) #
session.commit() #
rows = list(session.execute(
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"' #
))
assert rows == [("batch1", "RUSTY-SOAPDISH", 100, None)]
repo.add() это тестируемый здесь метод. | |
Мы храним .commit() вне репозитория и возлагаем ответственность на вызывающего. В этом есть свои плюсы и минусы; некоторые из причин станут яснее, когда мы доберемся до [chapter_06_uow]. | |
| Используем необработанный SQL, чтобы убедиться, что были сохраненыправильные данные . |
Следующий тест включает в себя извлечение пакетов и распределений, поэтому он более сложный:
def insert_order_line(session):
session.execute( #
'INSERT INTO order_lines (orderid, sku, qty)'
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid="order1", sku="GENERIC-SOFA")
)
return orderline_id
def insert_batch(session, batch_id): #
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, "batch1")
insert_batch(session, "batch2")
insert_allocation(session, orderline_id, batch1_id) #
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get("batch1")
expected = model.Batch("batch1", "GENERIC-SOFA", 100, eta=None)
assert retrieved == expected # Batch.__eq__ only compares reference #
assert retrieved.sku == expected.sku # assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == { #
model.OrderLine("order1", "GENERIC-SOFA", 12),
}
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == { #
model.OrderLine("order1", "GENERIC-SOFA", 12),
}
Проверяет сторону чтения, поэтому необработанный SQL готовит данные для чтения repo.get(). | |
Избавляем вас от деталей insert_batch и insert_allocation; Зыдача в том, чтобы создать пару партий, а для интересующей нас партии выделить одну существующую строку заказа. | |
Вот что мы здесь проверяем. Первый assert == проверяет соответствие типов и совпадение ссылок (потому что, как вы помните, Batch — это сущность, и для нее у нас есть собственный eq ). | |
Поэтому мы также явно проверяем его основные атрибуты, в том числе ._allocations, который представляет собой набор Python-объектов значений OrderLine. |
Независимо от того, насколько вы кропотливо написали тесты для каждой модели. После того, как у вас будет протестирован один класс на создание/изменение/сохранение, вы можете продолжить и протестировать другие с минимальным тестом на обратную связь или вообще ничего, если все они следуют схожему шаблону. В нашем случае конфигурация ORM, которая устанавливает набор ._allocations, немного сложна, поэтому заслуживает особого тестирования.
Вы получите что-то вроде этого:
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()
И теперь наша конечная точка Flask может выглядеть примерно так:
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty'])
for l in request.params...
]
allocate(lines, batches)
session.commit()
return 201
Создание поддельного репозитория для тестов теперь тривиально!
Вот одно из самых больших преимуществ шаблона репозиторий:
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)
Поскольку это простая оболочка для set, все методы являются однострочными.
Использовать фальшивое репо в тестах действительно просто, и у нас есть простая абстракция, которую легко использовать и рассуждать:
fake_repo = FakeRepository([batch1, batch2, batch3])
Вы увидите эту подделку в действии в следующей главе.
| Создание подделок для ваших абстракций - отличный способ получить обратную связь от дизайна: если подделать сложно, значит, абстракция слишком сложна. |
Что такое порт и что такое адаптер в Python?
Мы не хотим слишком подробно останавливаться здесь на терминологии, потому что главное, на чем мы хотим сосредоточиться, - это инверсия зависимостей, а специфика используемой вами техники не имеет большого значения. Кроме того, мы знаем, что разные люди используют несколько разные определения.
Порты и адаптеры вышли из мира OO, и определение, которое мы придерживаемся, состоит в том, что port — это interface между нашим приложением и тем, что мы хотим абстрагировать, а adapter — это implementation (реализация) за этим интерфейсом или абстракцией.
Python не имеет интерфейсов как таковых, поэтому, хотя обычно легко идентифицировать адаптер, определение порта может быть сложнее. Если вы используете абстрактный базовый класс, это порт. Если нет, то порт—это просто duck type, которому соответствуют ваши адаптеры и который ожидает ваше основное приложение — имена используемых функций и методов, а также имена и типы их аргументов.
Конкретно, в этой главе, AbstractRepository это порт, a SqlAlchemyRepository и FakeRepository - это адаптеры.
Заключение
Помня цитату Рича Хики, в каждой главе мы суммируем затраты и преимущества каждого представленного архитектурного шаблона. Мы хотим, чтобы было ясно, что мы не говорим, что каждое отдельное приложение должно быть построено именно таким образом; только иногда сложность приложения и домена заставляет тратить время и усилия на добавление этих дополнительных слоев косвенности.
Имея это в виду, [chapter_02_repository_tradeoffs] показывает некоторые плюсы и минусы шаблона репозитория и нашей модели с игнорированием персистентности.
| Плюсы | Минусы |
|---|---|
|
|
[domain_model_tradeoffs_diagram] демонстрирует основной тезис: да, для простых случаев развязанная модель предметной области является более сложной работой, чем простой шаблон ORM/ActiveRecord.[8]
| Если ваше приложение представляет собой простую оболочку CRUD (создание-чтение-обновление-удаление) вокруг базы данных, вам не нужна модель предметной области или репозиторий. |
Но чем сложнее домен, тем больше окупаются инвестиции в избавление от проблем с инфраструктурой с точки зрения простоты внесения изменений.
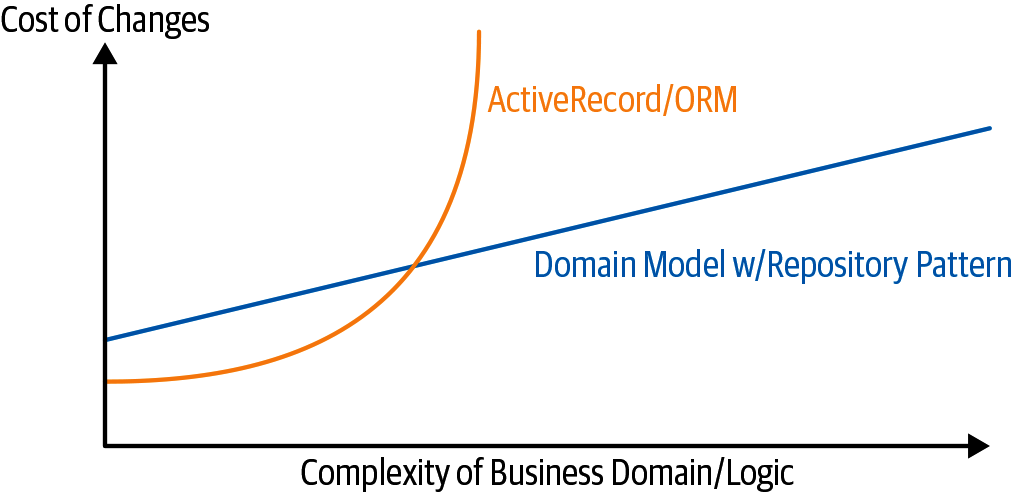
Наш пример кода не настолько сложен, чтобы дать больше, чем намек на то, как выглядит правая часть графика, но намеки есть. Представьте себе, например, что однажды мы решим, что хотим изменить распределение, чтобы жить на "OrderLine", а не на "Batch" объекте: если бы мы использовали, скажем, Django, нам пришлось бы определить и продумать миграцию базы данных, прежде чем мы могли бы запустить какие-либо тесты. Как бы то ни было, поскольку наша модель-это просто старые объекты Python, мы можем изменить set() на новый атрибут, не думая о базе данных до более подходящего момента.
Вам будет интересно, как мы создаем экземпляры этих хранилищ, поддельные или настоящие? Как на самом деле будет выглядеть наше приложение Flask? Вы узнаете об этом в следующей захватывающей части, the Service Layer pattern.
Но сначала небольшое отступление.
list, delete или update?" Однако в идеальном мире мы модифицируем объекты нашей модели по одному, а удаление обычно обрабатывается как мягкое удаление, то есть batch.cancel (). Наконец, об обновлении позаботится шаблон Unit of Work, как вы увидите в [chapter_06_uow].pylint и mypy.

Комментарии
Отправить комментарий