4.Наш первый Use Case или пример использования: Flask API и Service Layer
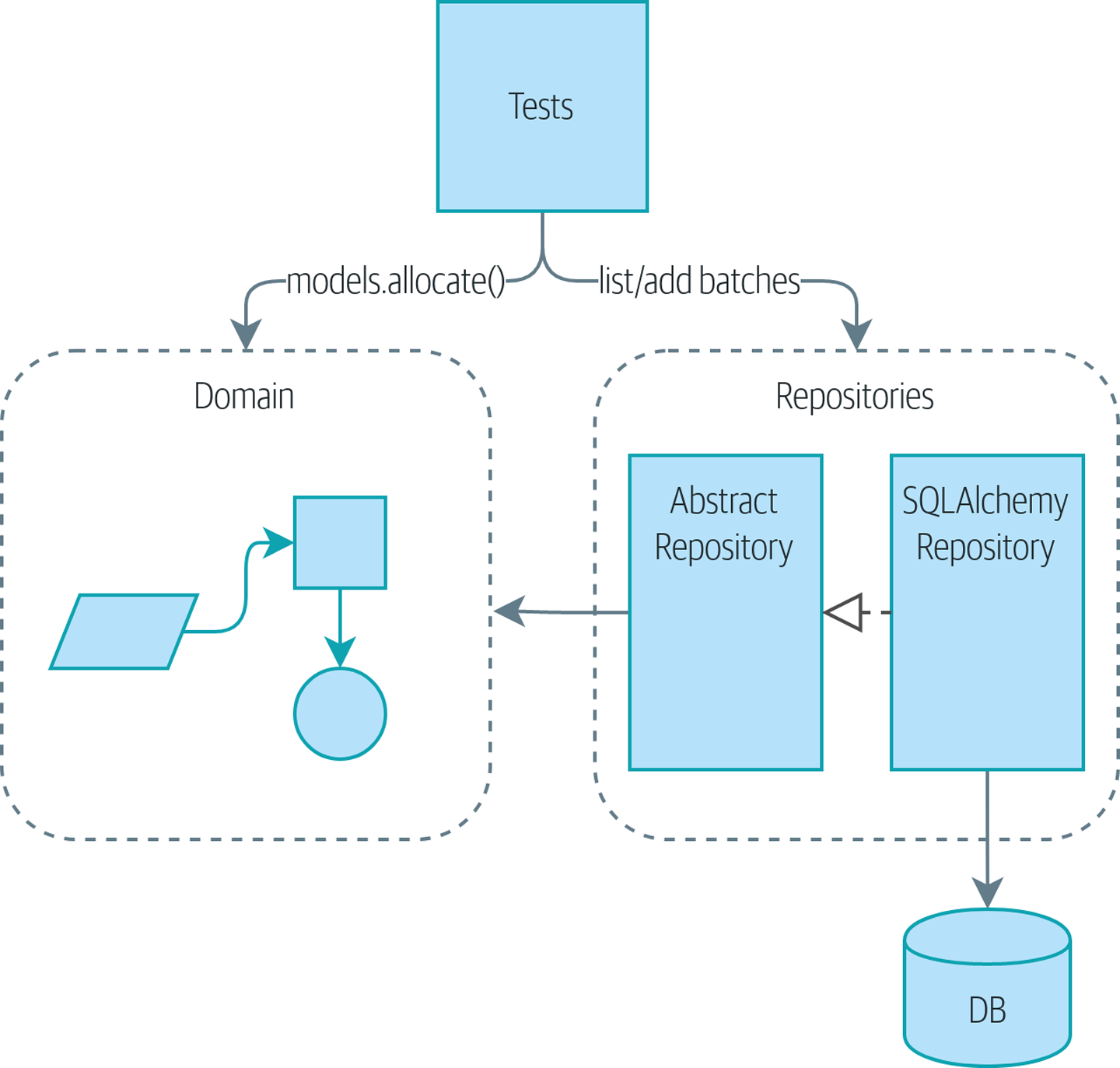
Вернемся к нашему исходному проекту! Схема [maps_service_layer_before] показывает точку, которую мы достигли в конце [chapter_02_repository], которая включает в себя шаблон репозитория.
В этой главе мы обсудим различие между Orchestration logic, business logic и interfacing code, а также введем модель Service Layer для координации наших бизнес - процессов и определения вариантов использования системы.
Мы также обсудим тестирование: объединив уровень сервиса с нашей абстракцией репозитория над базой данных, мы можем писать быстрые тесты не только нашей модели предметной области, но и всего рабочего процесса для конкретного случая использования.
Схема [maps_service_layer_after] показывает, то к чему мы стремимся: Собираемся добавить API Flask, который будет общаться с уровнем сервиса, который будет служить точкой входа в нашу доменную модель. Поскольку наш уровень обслуживания зависит от AbstractRepository, мы можем модульно протестировать его с помощью FakeRepository, но запустить наш production код с помощью SqlAlchemyRepository.
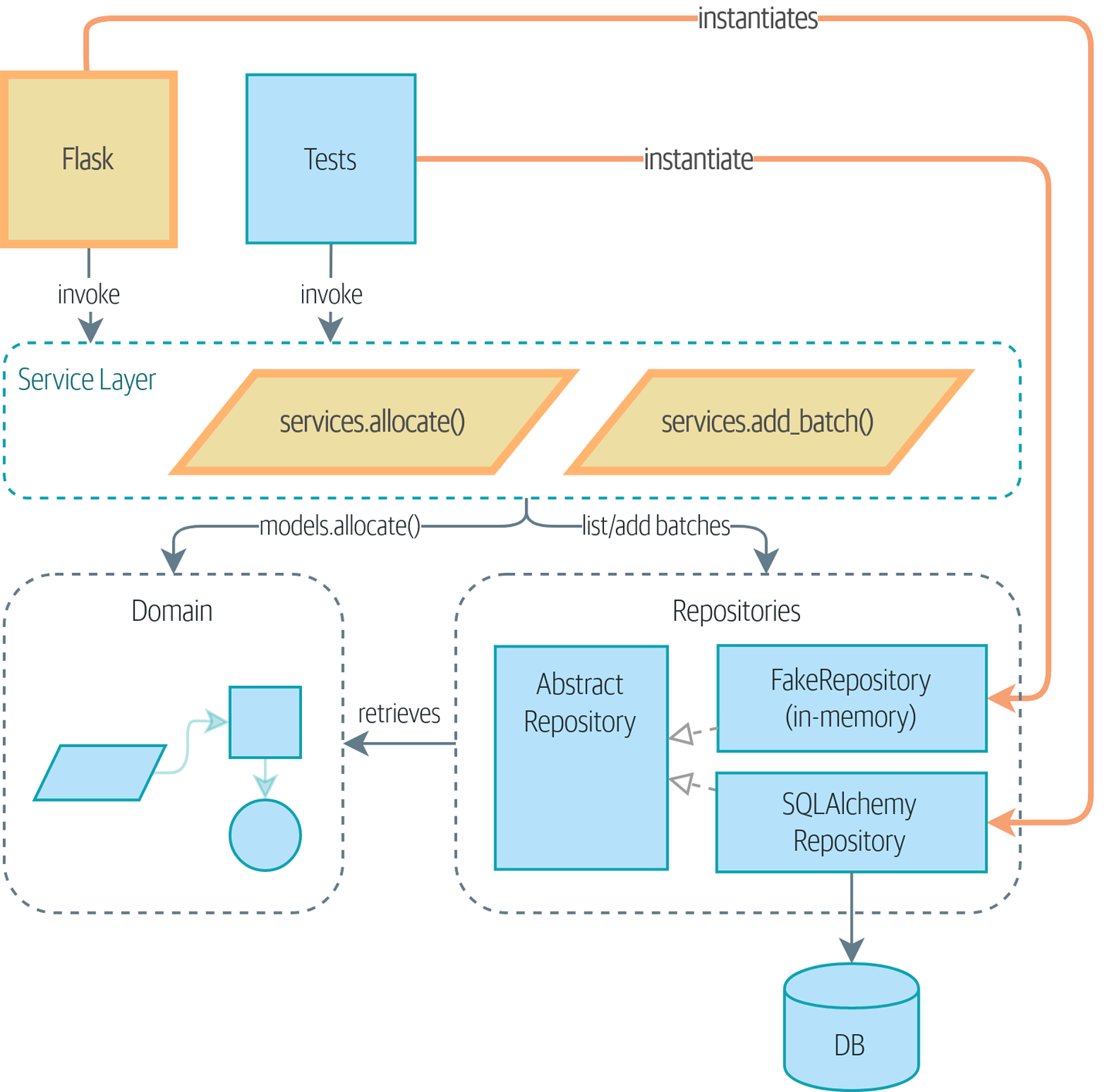
В наших диаграммах мы используем соглашение о том, что новые компоненты выделяются жирным шрифтом/линиями (и желтым/оранжевым цветом, если вы читаете цифровую версию).
Код этой главы находится в ветке chapter_04_service_layer on GitHub: |
Подключение нашего приложения к реальному миру
Как и любая другая команда, быстрая и проворная, мы пытаемся получить MVP (минимально жизнеспособный продукт) и собрать обратную связь на глазах у пользователей. У нас есть ядро нашей доменной модели и доменная служба, необходимая для распределения заказов, а также интерфейс репозитория для постоянного хранилища.
Давайте как можно скорее соединим все мобильные компоненты и перестроим их в более чистую архитектуру. Наш план таков:
Используем Flask, чтобы поместить endpoint API перед сервисом
allocate. Подключаем сеанс базы данных и наш репозиторий. Тестируем его с помощью сквозного теста и некоторого quick-and-dirty SQL для подготовки тестовых данных. Проводим сеанс работы с базой данных и нашим репозиторием. Протестируем его с помощью сквозного теста и небольшого количества quick-and-dirty SQL запросов для подготовки тестовых данных.Отрефакторим сервисный уровень, который будет служить абстракцией для захвата сценария использования и который будет находиться между Flask и нашей моделью домена. Построим несколько тестов сервисного уровня и покажем, как они могут использовать
FakeRepository.Поэкспериментируем с различными типами параметров для наших функций сервисного уровня; продемонстрируем, что использование примитивных типов данных позволяет отделить клиентов сервисного уровня (наши тесты и наш API Flask) от уровня модели.
Первый сквозной тест
Никто не заинтересован в долгих терминологических дебатах о том, что считается сквозным тестом (E2E) по сравнению с функциональным тестом по сравнению с приемочным тестом по сравнению с интеграционным тестом по сравнению с модульным тестом. Различные проекты нуждаются в различных комбинациях тестов, и мы видели, как совершенно успешные проекты просто делят вещи на "быстрые тесты" и "медленные тесты"."
На данный момент мы хотим написать один или, может быть, два теста, которые будут использовать "реальную" конечную точку API (используя HTTP) и общаться с реальной базой данных. Давайте назовем их сквозные тесты, потому что это одно из самых понятных названий.
Ниже показан первый разрез:
@pytest.mark.usefixtures('restart_api')
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku('other') # earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([ #
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([ # (laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url() #
(laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url() # r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
random_sku(), random_batchref () и так далее — это небольшие вспомогательные функции, которые генерируют случайные символы с помощью модуля uuid. Поскольку сейчас мы работаем с реальной базой данных, это один из способов предотвратить взаимное влияние различных тестов друг на друга. | |
add_stock — это вспомогательная фикстура, инструмент, который просто скрывает детали ручной вставки строк в базу данных с помощью SQL. В конце этой главы мы покажем способ получше. | |
| config.py это модуль, в котором мы храним информацию о конфигурации. |
Все решают эти проблемы по-разному, но вам понадобится какой-то способ развернуть Flask, возможно, в контейнере, и пообщаться с базой данных Postgres. Если вы хотите увидеть, как мы это сделали, ознакомьтесь [appendix_project_structure].
Простая Реализация
Реализуя вещи самым очевидным образом, вы можете получить что-то вроде этого:
from flask import Flask, jsonify, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
batchref = model.allocate(line, batches)
return jsonify({'batchref': batchref}), 201
Пока всё слишком хорошо. Боб и Гарри, вы наверное думаете, что вам больше не нужно говорить про "архитектурных астронавтов".
Но подождите минутку — никаких обязательств. На самом деле мы не сохраняем наше распределение в базе данных. Теперь нам нужен второй тест, либо тот, который проверит состояние базы данных после (не очень black-boxy чёрного ящика), или, может быть, тот, который проверяет, что мы не можем выделить вторую строку, если первая уже должна была исчерпать пакет:
@pytest.mark.usefixtures('restart_api')
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock([
(batch1, sku, 10, '2011-01-01'),
(batch2, sku, 10, '2011-01-02'),
])
line1 = {'orderid': order1, 'sku': sku, 'qty': 10}
line2 = {'orderid': order2, 'sku': sku, 'qty': 10}
url = config.get_api_url()
# первый заказ использует все запасы в партии 1
r = requests.post(f'{url}/allocate', json=line1)
assert r.status_code == 201
assert r.json()['batchref'] == batch1
# второй заказ должен перейти в партию 2
r = requests.post(f'{url}/allocate', json=line2)
assert r.status_code == 201
assert r.json()['batchref'] == batch2
Не совсем так красиво, но это заставит нас добавить коммит.
Ошибочные условия требуют проверки базы данных
Если мы будем продолжать в том же духе, все станет ещё хуже и хуже.
Предположим, что мы добавим несколько обработок ошибок. Что делать, если домен вызывает ошибку для SKU, которого нет в наличии? Или как насчет SKU, которого даже не существует? Об этом домен даже не знает, да и не должен знать. Это скорее проверка на вменяемость, которую мы должны применить на уровне базы данных, прежде чем мы даже вызовем службу домена.
Теперь мы рассмотрим еще пару сквозных теста:
@pytest.mark.usefixtures('restart_api')
def test_400_message_for_out_of_stock(add_stock): #
sku, smalL_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock([
(smalL_batch, sku, 10, '2011-01-01'),
])
data = {'orderid': large_order, 'sku': sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Out of stock for sku {sku}'
@pytest.mark.usefixtures('restart_api')
def test_400_message_for_invalid_sku(): #
unknown_sku, orderid = random_sku(), random_orderid()
data = {'orderid': orderid, 'sku': unknown_sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'
| В первом тесте мы пытаемся выделить больше единиц, чем есть на складе. | |
Во втором случае SKU просто не существует (потому что мы никогда не вызывали add_stock), поэтому он недействителен для нашего приложения. |
И конечно, мы могли бы реализовать его и в приложении Flask:
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
if not is_valid_sku(line.sku, batches):
return jsonify({'message': f'Invalid sku {line.sku}'}), 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return jsonify({'message': str(e)}), 400
session.commit()
return jsonify({'batchref': batchref}), 201
Но наше приложение Flask начинает выглядеть слегка громоздким. И наше количество тестов E2E начинает выходить из-под контроля, и вскоре мы получим перевернутую тестовую пирамиду (или "модель рожка мороженого", как любит называть ее Боб).
Представляем сервисный слой и используем FakeRepository для его модульного тестирования
Если мы посмотрим на то, что делает наше приложение Flask, то увидим довольно много того, что мы могли бы назвать orchestration —- извлечение материала из нашего репозитория, проверка наших входных данных на соответствие состоянию базы данных, обработка ошибок и фиксация в happy path. Большинство из этих вещей не имеют ничего общего с наличием web API endpoint (они понадобились бы вам, если бы вы создавали, например CLI; см. [appendix_csvs]), и на самом деле это не те вещи, которые нужно тестировать сквозными тестами.
Часто имеет смысл разделить service layer, иногда называемый orchestration layer слоем оркестровки или use-case слоем прецедентов .
Вы помните "FakeRepository", который мы подготовили в [chapter_03_abstractions]?
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)
Вот где он будет полезен; он позволяет нам тестировать наш уровень обслуживания с помощью хороших, быстрых модульных тестов:
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) #
result = services.allocate(line, repo, FakeSession()) #
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) #
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) #
FakeRepository содержит объекты Batch, которые будут использоваться в нашем тесте. | |
Наш сервисный модуль (services.py) определит функцию сервисного уровня allocate(). Он будет находиться между нашей функцией allocate_endpoint() на уровне API и функцией доменной службы allocate() из нашей модели домена.[1] | |
| Нам также нужен "FakeSession", чтобы подделать сеанс базы данных, как показано в следующем фрагменте кода. |
class FakeSession():
committed = False
def commit(self):
self.committed = True
Эта фальшивая сессия - лишь временное решение. Мы скоро избавимся от него и сделаем все лучше. [chapter_06_uow]. Но в то же время фейковый .commit() позволяет нам перенести третий тест со слоя E2E:
def test_commits():
line = model.OrderLine('o1', 'OMINOUS-MIRROR', 10)
batch = model.Batch('b1', 'OMINOUS-MIRROR', 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is True
Типичная Service Function
Мы напишем служебную функцию, которая выглядит примерно так:
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() #
if not is_valid_sku(line.sku, batches): #
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = model.allocate(line, batches) #
session.commit() # return batchref
return batchref
Типичные функции сервисного уровня имеют сходные этапы:
| Извлекаем некоторые объекты из репозитория. | |
| Мы делаем несколько подтверждений или опровергаем требования о текущем состоянии мира. | |
| Мы вызываем доменную службу. | |
| Если все хорошо, то мы сохраняем/обновляем любое состояние, которое мы изменили. |
Этот последний шаг на данный момент несовсем удовлетворителен, поскольку наш сервисный уровень тесно связан с нашим уровнем базы данных. Мы улучшим это в [chapter_06_uow] с помощью шаблона Unit of Work.
Но самое необходимое для уровня сервиса уже есть, и наше приложение Flask теперь выглядит намного чище:
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session() #
repo = repository.SqlAlchemyRepository(session) #
line = model.OrderLine(
request.json['orderid'], #
request.json['sku'], #
request.json['qty'], #
)
try:
batchref = services.allocate(line, repo, session) #
except (model.OutOfStock, services.InvalidSku) as e:
return jsonify({'message': str(e)}), 400 #
return jsonify({'batchref': batchref}), 201 #
| Инстанцируем сеанс работы с базой данных и некоторые объекты репозитория. | |
| Извлекаем команды пользователя из веб-запроса и передаем их службе домена. | |
| Возвращаем несколько ответов JSON с соответствующими кодами состояния. |
Обязанности приложения Flask - это обычные веб-вещи: управление сеансами по каждому запросу, анализ информации из параметров POST, коды состояния ответа и JSON. Вся логика оркестрации находится на уровне использования case/service, а логика домена остается в домене.
Наконец, мы можем уверенно разделить наши тесты E2E всего на два: один для пути удачных решений и один для неверного выбора:
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([
(laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
@pytest.mark.usefixtures('restart_api')
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {'orderid': orderid, 'sku': unknown_sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'
Мы успешно разделили наши тесты на две большие категории: тесты на веб-материалы, которые мы реализуем от начала до конца; и тесты, связанные с оркестровкой, которые мы можем протестировать на уровне сервиса в памяти.
Теперь, когда у нас есть служба распределения, почему бы не создать службу для освобождения? Мы добавили тест E2E и несколько тестов stub для уровня сервиса для вас, чтобы начать работу на GitHub.
Если этого недостаточно, переходите к тестам E2E и flask_app.py и отрефакторите адаптер Flask, чтобы он был более RESTful. Обратите внимание, что это не требует каких-либо изменений в нашем сервисном или доменном слое!
Если вы решили, что хотите создать конечную точку read-only для получения информации о выделении, просто сделайте «простейшую вещь, которая может сработать», а именно repo.get() прямо в обработчике Flask. Мы поговорим больше о чтении и записи в [chapter_12_cqrs]. |
Почему всё называется сервисом?
Некоторые из вас, вероятно, сейчас ломают голову, пытаясь точно понять, в чем разница между доменным сервисом и уровнем сервиса.
К сожалению, не мы выбрали имена, иначе у нас были бы более разумные и дружелюбные способы поговорить об этом.
В этой главе мы используем две вещи, называемые service. Первый-это application service (наш service layer). Его работа заключается в обработке запросов из внешнего мира и в orchestrate операции. Мы имеем в виду, что уровень сервиса управляет приложением, следуя нескольким простым шагам:
Получить некоторые данные из базы данных
Обновить модели домена
Сохранить любые изменения
Это рутина, которая должна выполняться для каждой операции в вашей системе, и отделение её от бизнес-логики помогает поддерживать порядок.
Второй тип сервиса-это domain service. Это имя для части логики, которая принадлежит модели предметной области, но не находится естественным образом внутри состояния сущности или value object. Например, если вы создаете приложение для корзины покупок, вы можете выбрать создание правил налогообложения в качестве доменной службы. Расчет налога-это отдельная работа от обновления корзины, и это важная часть модели, но не кажется правильным иметь постоянную сущность для этой работы. Вместо этого эту работу может выполнять класс TaxCalculator или функция calculate_tax.
Разложим всё по папкам, чтобы увидеть, чему всё это принадлежит
По мере того, как приложения становятся все больше и больше, нам необходимо постоянно обновлять структуру каталогов. Компоновка проекта предоставляет полезные советы о том, что в каком файле находится.
Мы можем организовать все так:
.
├── config.py
├── domain #
│ ├── __init__.py
│ └── model.py
├── service_layer #
│ ├── __init__.py
│ └── services.py
├── adapters #
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py
Давайте создадим папку для нашей доменной модели. В настоящее время это всего лишь один файл, но для более сложного приложения у вас может быть один файл на класс; у вас могут быть вспомогательные родительские классы для Entity, ValueObject, и Aggregate, и вы могли бы добавить exceptions.py для исключений доменного уровня и, как вы увидите в [part2], commands.py и events.py. | |
| Мы будем различать уровень обслуживания. В настоящее время это всего лишь один файл с именем services.py для наших функций сервисного уровня. Здесь вы можете добавить исключения сервисного уровня, и, как вы увидите в [chapter_05_high_gear_low_gear], мы добавим unit_of_work.py. | |
| Adapters - это дань терминологии портов и адаптеров. Это заполнит любые другие абстракции вокруг внешнего I/O (напр., a redis_client.py). Строго говоря, вы бы назвали эти адаптеры secondary или driven адаптерами, или иногда inward-facing адаптерами. | |
| Точки входа entrypoints — это места, откуда мы управляем нашим приложением. В официальной терминологии портов и адаптеров они тоже являются адаптерами и называются адаптерами primary первичными, driving управляющими или outward-facing обращенными наружу. |
А как насчет портов? Как вы помните, это абстрактные интерфейсы, которые реализуют адаптеры. Мы склонны хранить их в том же файле, что и адаптеры, которые их реализуют.
Резюме
Добавление service layer уровня сервиса даёт немало преимуществ.
Наши entrypoints Flask API становятся очень тонкими и легкими в написании: их единственная обязанность-делать "web stuff", такие как разбор JSON и создание правильных HTTP-кодов для удачных или неудачных случаев.
Мы определили четкий API для нашего домена, набор вариантов использования или точек входа, которые могут быть использованы любым адаптером без необходимости знать что-либо о наших классах моделей домена-будь то API, CLI (см. [appendix_csvs]) или тесты! Они также являются адаптером для нашего домена.
Мы можем писать тесты на «высокой скорости», используя уровень сервиса, что дает нам возможность рефакторинга модели предметной области любым способом, который мы сочтем нужным. Пока мы можем предоставлять те же сценарии использования, мы можем экспериментировать с новыми проектами без необходимости переписывать множество тестов.
И наша пирамида тестирования выглядит неплохо — большая часть наших тестов — это быстрые модульные тесты, с минимальным количеством E2E и интеграционных тестов.
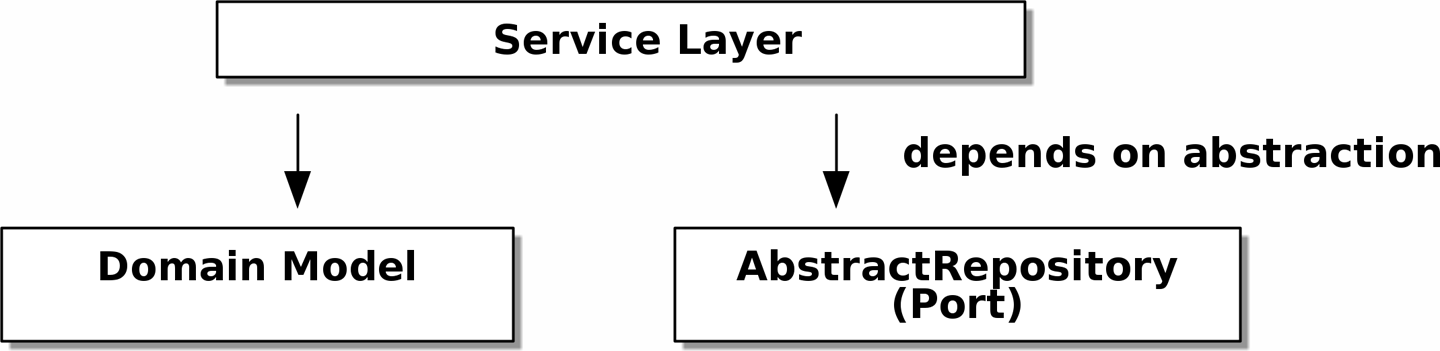
DIP в действии
[service_layer_diagram_abstract_dependencies] показывает зависимости нашего уровня сервиса: модель предметной области и AbstractRepository (порт в терминологии портов и адаптеров).
Когда мы запускаем тесты, [service_layer_diagram_test_dependencies] показывает, как мы реализуем абстрактные зависимости с помощью FakeRepository (адаптера).
И когда мы на самом деле запускаем наше приложение, мы меняем "реальную" зависимость, показанную в [service_layer_diagram_runtime_dependencies].

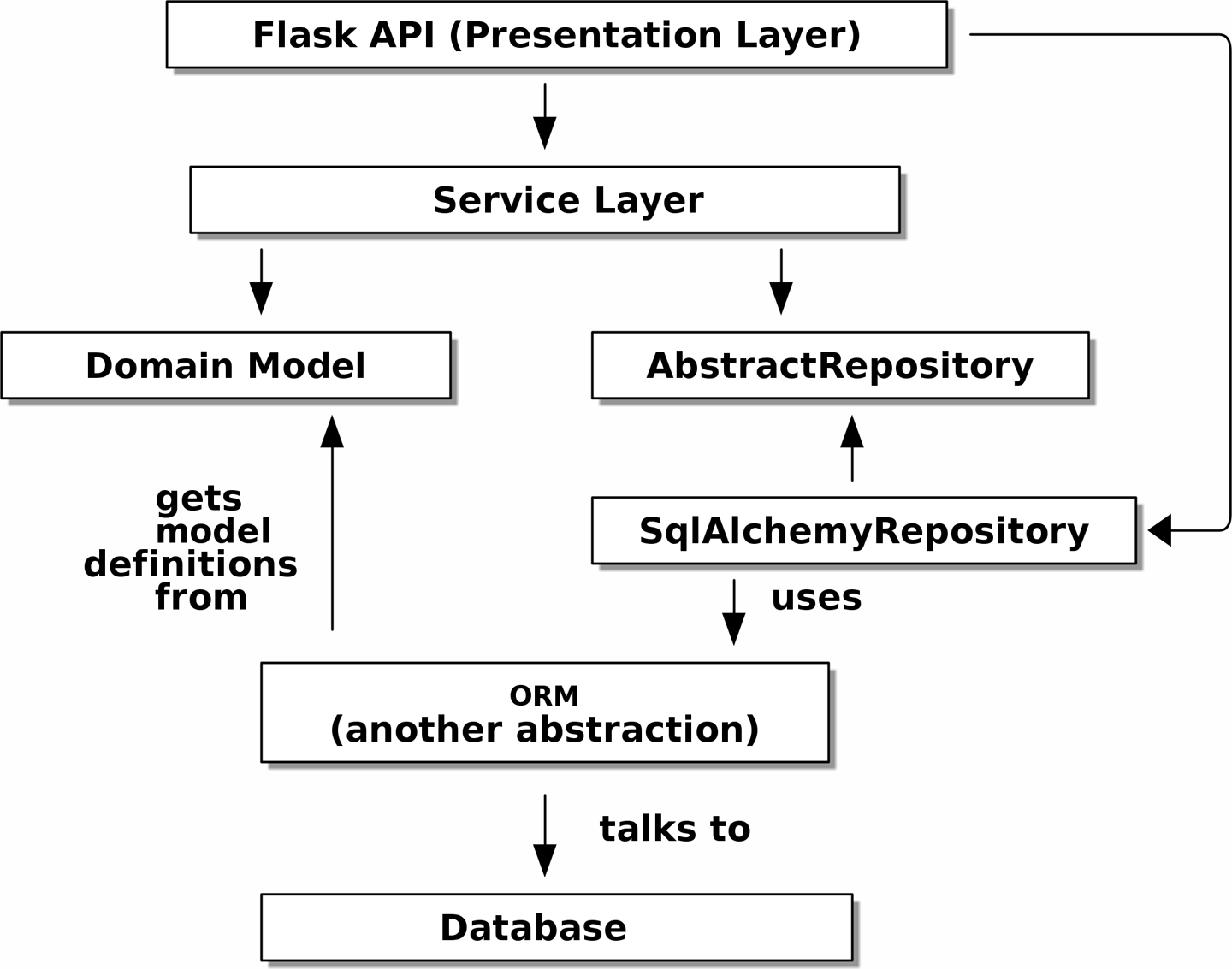
Чудесно.
Давайте сделаем паузу для [chapter_04_service_layer_tradeoffs], в которой мы рассмотрим плюсы и минусы наличия service layer вообще.
| Плюсы | Минусы |
|---|---|
|
|
Но есть еще несколько неловких моментов, которые нужно убрать:
Уровень сервиса по-прежнему тесно связан с доменом, поскольку его API выражается в терминах объектов
OrderLine. В [chapter_05_high_gear_low_gear] мы исправим это и поговорим о том, как уровень сервиса обеспечивает более производительный TDD.Уровень сервиса тесно связан с объектом
session. В [chapter_06_uow] мы введем еще один паттерн, который тесно работает с паттернами Уровня Репозитория и Сервиса, паттерн Unit of Work, и все будет абсолютно прекрасно. Вот увидите!


Комментарии
Отправить комментарий