9.Едем в город на автобусе сообщений
Едем в город на автобусе сообщений
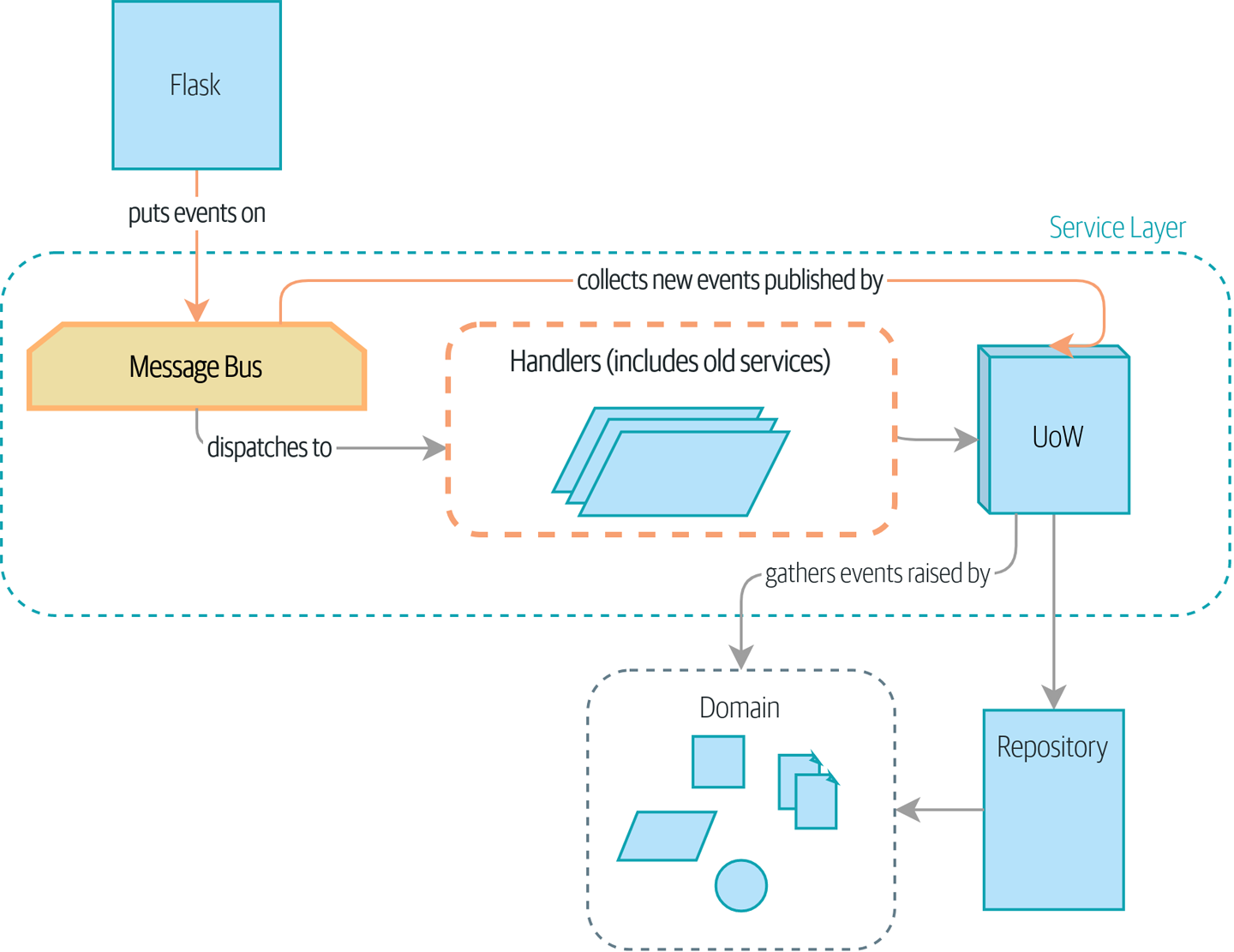
В этой главе мы начнем делать события более фундаментальными для внутренней структуры нашего приложения. Мы перейдем из текущего состояния в [maps_chapter_08_before], где события являются необязательным побочным эффектом …

…к ситуации в [map_chapter_08_after], где всё идет по шине сообщений, а наше приложение было принципиально преобразовано в процессор сообщений.
Код для этой главы находится в ветке chapter_09_all_messagebus. на GitHub: |
Новое требование приводит нас к новой архитектуре
Рич Хикки говорит о situated software, то есть о программном обеспечении, которое работает в течение длительных периодов времени, управляя реальным процессом. Примеры включают системы управления складом, логистические планировщики и системы расчета заработной платы.
Такое программное обеспечение сложно написать, потому что в реальном мире физических объектов и ненадежных людей постоянно происходят неожиданные вещи. Например:
Во время инвентаризации мы обнаруживаем, что три <код>ПРУЖИННЫЙ МАТРАСбыли повреждены водой из-за протекающей крыши.
У груза
RELIABLE-FORKs отсутствует необходимая документация и он застрял на таможне, где находится уже в течение нескольких недель. ТриRELIABLE-FORKs впоследствии не проходят проверку безопасности и уничтожаются.Глобальная нехватка блесток означает, что мы не сможем изготовить следующую партию
SPARKLY-BOOKCASE.
В таких ситуациях мы узнаем о необходимости изменения количества партий, когда они уже находятся в системе. Может быть, кто-то ошибся номером в декларации, а может быть, какие-то диваны упали с грузовика. После разговора с представителями компании[1] мы моделируем ситуацию, как на [batch_changed_events_flow_diagram].

Событие, которое мы назовем BatchQuantityChanged, должно привести нас к изменению количества в партии, да, но также и к применению бизнес правила: если новое количество опускается до меньшего, чем уже распределённое общее количество, нам нужно dealocate освободить места в этих заказы из этой партии. Затем каждый из них потребует нового распределения, которое мы можем зафиксировать как событие под названием AllocationRequired Требуемое распределение.
Возможно, вы уже ожидаете, что наша внутренняя шина сообщений и события помогут реализовать это требование. Мы могли бы определить службу под названием change_batch_quantity, которая знает, как корректировать количество партий, а также как deallocate (освобождать) любые избыточные строки заказа, а затем каждое освобождение может генерировать событие AllocationRequired, которое может быть перенаправлено существующей службе allocate (распределения) в отдельные транзакции. И снова наша шина сообщений помогает нам обеспечивать соблюдение принципа единой ответственности и позволяет нам делать выбор в отношении транзакций и целостности данных.
Представим себе изменение архитектуры: всё будет event handler Обработчик событий
Но прежде чем запрыгнуть в это, подумай, куда мы направляемся. Существует два вида потоков через нашу систему:
Вызовы API, которые обрабатываются функцией уровня сервиса
Внутренние события (которые могут быть вызваны как побочный эффект функции уровня сервиса) и их обработчики (которые, в свою очередь, вызывают функции уровня сервиса)
Разве не было бы проще, если бы все было обработчиком событий? Если мы переосмыслим наши вызовы API как захват событий, функции уровня сервиса также могут быть обработчиками событий, и нам больше не нужно проводить различие между внутренними и внешними обработчиками событий:
services.allocate()может быть обработчиком событияAllocationRequiredи может выдавать событияAllocatedв качестве его выходных данных.services.add_batch()может быть обработчиком событияBatchCreated.[2]
Наше новое требование будет соответствовать той же схеме:
Событие под названием
BatchQuantityChangedможет вызывать обработчик под названиемchange_batch_quantity().И новые события
AllocationRequired, которые он может вызвать, также могут быть переданы в `services.allocate() `, поэтому нет концептуальной разницы между совершенно новым распределением, исходящим от API, и перераспределением, которое запускается изнутри deallocate.
Все это звучит как-то чересчур? Давайте работать над всем этим постепенно. Мы будем следовать за рабочим процессом Подготовительный рефакторинг, он же гласит "Сделайте изменение легким; затем сделайте легкое изменение":
Мы рефакторингуем наш уровень обслуживания в обработчики событий. Мы можем привыкнуть к идее о том, что события-это способ описания входов в систему. В частности, существующая функция
services.allocate()станет обработчиком события под названиемAllocationRequired.Мы создаем сквозной тест,который помещает события
BatchQuantityChangedв систему и принимает выходящие событияAllocated.Наша реализация концептуально будет очень простой: новый обработчик событий
BatchQuantityChanged, реализация которого будет выдавать событияAllocationRequired, которые, в свою очередь, будут обрабатываться точно таким же обработчиком распределений, который использует API.
По пути мы сделаем небольшую настройку шины сообщений и UoW, перенеся ответственность за размещение (put) новых событий на шине сообщений в саму шину сообщений.
Рефакторинг сервисных функций для обработчиков сообщений
Мы начинаем с определения двух событий, которые фиксируют наши текущие входные данные API - AllocationRequired и BatchCreated:
@dataclass
class BatchCreated(Event):
ref: str
sku: str
qty: int
eta: Optional[date] = None
...
@dataclass
class AllocationRequired(Event):
orderid: str
sku: str
qty: int
Затем мы переименовываем services.py в handlers.py; мы добавляем обработчик текущих сообщений для send_out_of_stock_notification; и самое главное, мы меняем все обработчики так, чтобы у них были одинаковые входные данные, событие и UoW:
def add_batch(
event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=event.sku)
...
def allocate(
event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(event.orderid, event.sku, event.qty)
...
def send_out_of_stock_notification(
event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
):
email.send(
'stock@made.com',
f'Out of stock for {event.sku}',
)
Это изменение станет более ясным если помотреть на различие:
def add_batch(
- ref: str, sku: str, qty: int, eta: Optional[date],
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
- product = uow.products.get(sku=sku)
+ product = uow.products.get(sku=event.sku)
...
def allocate(
- orderid: str, sku: str, qty: int,
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
- line = OrderLine(orderid, sku, qty)
+ line = OrderLine(event.orderid, event.sku, event.qty)
...
+
+def send_out_of_stock_notification(
+ event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
+):
+ email.send(
...
Попутно мы сделали API нашего сервисного уровня более структурированным и последовательным. Это было рассеяние примитивов, и теперь используются четко определенные объекты (см. Следующую главу).
The Message Bus Now Collects Events from the UoW
Наши обработчики событий теперь нуждаются в UoW. Кроме того, поскольку наша шина сообщений становится всё более центральной для нашего приложения, имеет смысл явно возложить на неё ответственность за сбор и обработку новых событий. До сих пор существовала некоторая циклическая зависимость между UoW и шиной сообщений, так что это сделает её односторонней. Вместо того, чтобы иметь события UoW push на шине сообщений, мы будем иметь события message bus pull из UoW.
def handle(event: events.Event, uow: unit_of_work.AbstractUnitOfWork): # queue = [event] #
queue = [event] # while queue:
event = queue.pop(0) #
while queue:
event = queue.pop(0) # for handler in HANDLERS[type(event)]: #
handler(event, uow=uow) #
for handler in HANDLERS[type(event)]: #
handler(event, uow=uow) # queue.extend(uow.collect_new_events()) #
queue.extend(uow.collect_new_events()) #
| Шина сообщений теперь проходит UoW при каждом запуске. | |
| Когда мы начинаем обрабатывать наше первое событие, мы запускаем очередь. | |
Мы извлекаем события из передней части очереди и вызываем их обработчики (HANDLERS dict не изменился; он по-прежнему сопоставляет типы событий с функциями обработчиков). | |
| Шина сообщений передает UoW каждому обработчику. | |
| После завершения каждого обработчика мы собираем все новые сгенерированные события и добавляем их в очередь. |
В unit_of_work.py 'publish_events()` становится менее активным методом, collect_new_events():
-from . import messagebus #
-
class AbstractUnitOfWork(abc.ABC):
@@ -23,13 +21,11 @@ class AbstractUnitOfWork(abc.ABC):
def commit(self):
self._commit()
- self.publish_events() #
- def publish_events(self):
+ def collect_new_events(self):
for product in self.products.seen:
while product.events:
- event = product.events.pop(0)
- messagebus.handle(event)
+ yield product.events.pop(0) #
Модуль unit_of_work теперь больше не зависит от messagebus. | |
Мы больше не выполняем publish_events автоматически при фиксации. Вместо этого шина сообщений отслеживает очередь событий. | |
| И UoW больше не размещает активные события в шину сообщений; он просто делает их доступными. |
Наши тесты тоже написаны в терминах событий
Наши тесты теперь работают, создавая события и помещая их в шину сообщений, а не вызывая функции сервисного уровня напрямую:
class TestAddBatch:
def test_for_new_product(self):
uow = FakeUnitOfWork()
- services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow)
+ messagebus.handle(
+ events.BatchCreated("b1", "CRUNCHY-ARMCHAIR", 100, None), uow
+ )
assert uow.products.get("CRUNCHY-ARMCHAIR") is not None
assert uow.committed
...
class TestAllocate:
def test_returns_allocation(self):
uow = FakeUnitOfWork()
- services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow)
- result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow)
+ messagebus.handle(
+ events.BatchCreated("batch1", "COMPLICATED-LAMP", 100, None), uow
+ )
+ result = messagebus.handle(
+ events.AllocationRequired("o1", "COMPLICATED-LAMP", 10), uow
+ )
assert result == "batch1"
Временный Наглый Взлом: шина сообщений должна возвращать результаты
Наш API и наш уровень сервиса в настоящее время хотят узнать выделенную ссылку на пакет, когда они вызывают наш обработчик allocate(). Это означает, что нам нужно временно взломать нашу шину сообщений, чтобы она возвращала события:
def handle(event: events.Event, uow: unit_of_work.AbstractUnitOfWork):
+ results = []
queue = [event]
while queue:
event = queue.pop(0)
for handler in HANDLERS[type(event)]:
- handler(event, uow=uow)
+ results.append(handler(event, uow=uow))
queue.extend(uow.collect_new_events())
+ return results
Это потому, что мы смешиваем обязанности чтения и записи в нашей системе. Мы вернемся, чтобы исправить эту неприятность в [chapter_12_cqrs].
Изменение нашего API для работы с событиями
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
try:
- batchref = services.allocate(
- request.json['orderid'], #
- request.json['sku'],
- request.json['qty'],
- unit_of_work.SqlAlchemyUnitOfWork(),
+ event = events.AllocationRequired( #
+ request.json['orderid'], request.json['sku'], request.json['qty'],
)
+ results = messagebus.handle(event, unit_of_work.SqlAlchemyUnitOfWork()) #
+ batchref = results.pop(0)
except InvalidSku as e:
| Вместо вызова уровня сервиса с кучей примитивов, извлеченных из запроса JSON … | |
| Создаем событие. | |
| Затем передаем его в шину сообщений. |
И мы должны вернуться к полностью функциональному приложению, но теперь полностью управляемому событиями:
То, что раньше было функциями сервисного уровня, теперь стало обработчиками событий.
Это делает их такими же, как функции, которые мы вызываем для обработки внутренних событий, вызванных нашей моделью предметной области.
Мы используем события в качестве структуры данных для сбора входных данных в систему, а также для передачи внутренних рабочих пакетов.
Теперь все приложение лучше всего описать как процессор сообщений или, если хотите, процессор событий. Мы поговорим об этом различии в следующей главе[chapter_10_commands].
Реализация нашего нового требования (Requirement)
Мы закончили с фазой рефакторинга. Давайте посмотрим, действительно ли мы "сделали изменение легким." Давайте реализуем наше новое требование, показанное в [reallocation_sequence_diagram]: мы получим в качестве входных данных некоторые новые события BatchQuantityChanged и передадим их обработчику, который, в свою очередь, может выдать некоторые события AllocationRequired, а те, в свою очередь, вернутся к нашему существующему обработчику для перераспределения.
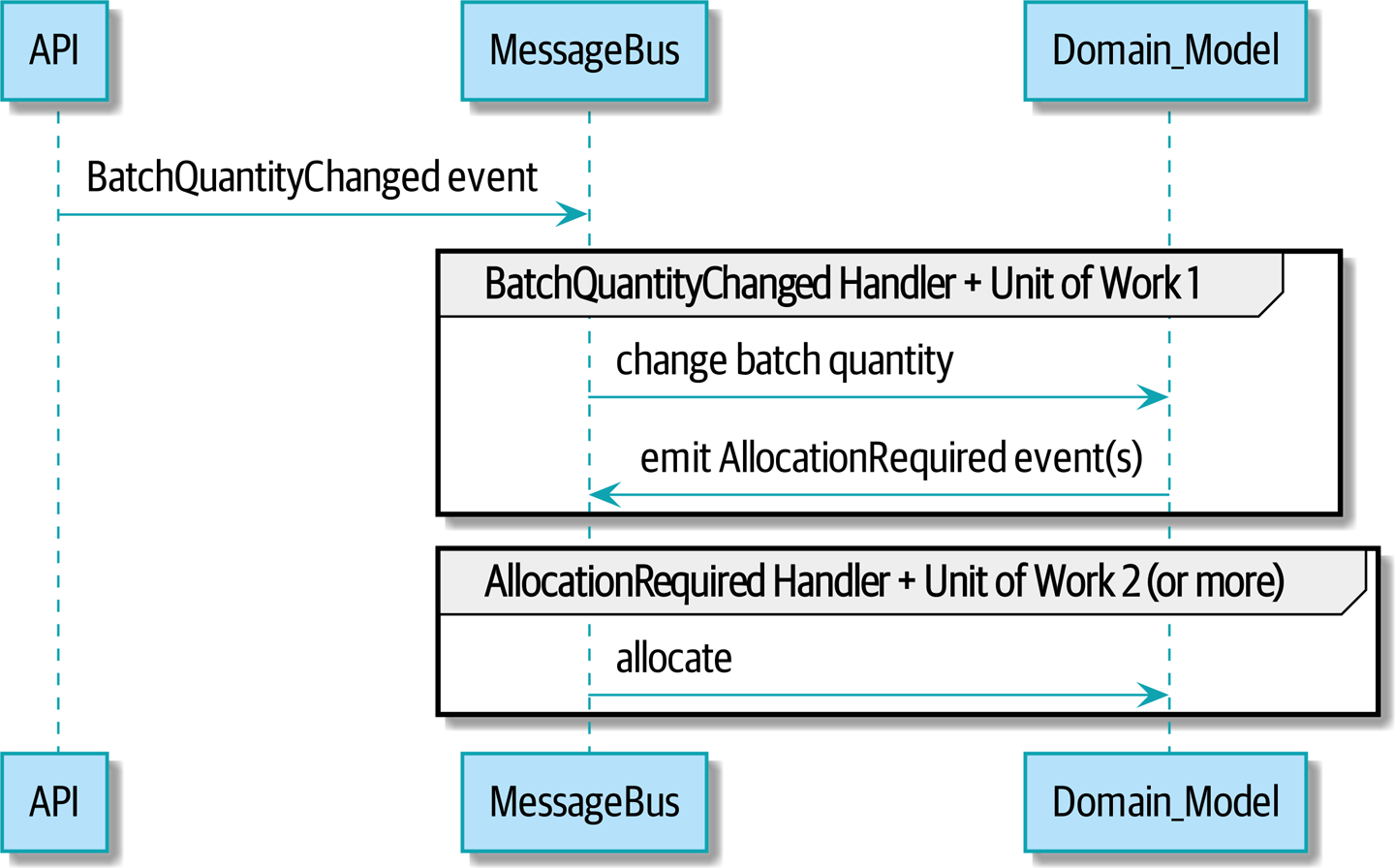
| Когда вы разделяете вещи таким образом на две единицы работы, то у вас получаются две транзакции базы данных, поэтому вы открываете себя для проблем целостности: что-то может произойти, и это означает, что первая транзакция завершается, а вторая-нет. Вам нужно будет подумать о том, приемлемо ли это, и нужно ли вам замечать, когда это происходит, и что-то с этим делать. См. [footguns] для более подробного обсуждения. |
Наше новое событие
Событие, которое говорит нам, что количество партии изменилось, простое; ему просто нужна ссылка на партию и новое количество:
@dataclass
class BatchQuantityChanged(Event):
ref: str
qty: int
Test-Driving нового Handler
Следуя урокам, извлеченным из [chapter_04_service_layer], мы можем работать на «высокой передаче» и писать наши модульные тесты на максимально возможном уровне абстракции с точки зрения событий. Вот как они могут выглядеть:
class TestChangeBatchQuantity:
def test_changes_available_quantity(self):
uow = FakeUnitOfWork()
messagebus.handle(
events.BatchCreated("batch1", "ADORABLE-SETTEE", 100, None), uow
)
[batch] = uow.products.get(sku="ADORABLE-SETTEE").batches
assert batch.available_quantity == 100 #
messagebus.handle(events.BatchQuantityChanged("batch1", 50), uow)
assert batch.available_quantity == 50 #
def test_reallocates_if_necessary(self):
uow = FakeUnitOfWork()
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# order1 or order2 will be deallocated, so we'll have 25 - 20
assert batch1.available_quantity == 5 #
# and 20 will be reallocated to the next batch
assert batch2.available_quantity == 30 #
| Простой случай будет тривиально легко реализовать; мы просто модифицируем количество. | |
| Но если мы попытаемся изменить количество на меньшее, чем было выделено, нам нужно будет исключить по крайней мере один заказ, и перераспределить его на новую ожидаемую партию. |
Реализация
Наш новый обработчик очень прост:
def change_batch_quantity(
event: events.BatchQuantityChanged, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get_by_batchref(batchref=event.ref)
product.change_batch_quantity(ref=event.ref, qty=event.qty)
uow.commit()
Мы понимаем, что нам понадобится новый тип запроса в нашем репозитории:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | class AbstractRepository(abc.ABC):
...
def get(self, sku) -> model.Product:
...
def get_by_batchref(self, batchref) -> model.Product:
product = self._get_by_batchref(batchref)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product):
raise NotImplementedError
@abc.abstractmethod
def _get(self, sku) -> model.Product:
raise NotImplementedError
@abc.abstractmethod
def _get_by_batchref(self, batchref) -> model.Product:
raise NotImplementedError
...
class SqlAlchemyRepository(AbstractRepository):
...
def _get(self, sku):
return self.session.query(model.Product).filter_by(sku=sku).first()
def _get_by_batchref(self, batchref):
return self.session.query(model.Product).join(model.Batch).filter(
orm.batches.c.reference == batchref,
).first()
|
И в нашем FakeRepository:
class FakeRepository(repository.AbstractRepository):
...
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
def _get_by_batchref(self, batchref):
return next((
p for p in self._products for b in p.batches
if b.reference == batchref
), None)
Мы добавляем запрос в наш репозиторий, чтобы упростить реализацию этого варианта использования. Пока наш запрос возвращает единственную совокупность, мы не нарушаем никаких правил. Если вы обнаружите, что пишете сложные запросы к своим репозиториям, возможно, вам захочется рассмотреть другой дизайн. Такие методы, как get_most_popular_products или find_products_by_order_id, в частности, определенно вызовут щекотку в области нашего шестого чувства. В [chapter_11_external_events] и epilogue есть несколько советов по управлению сложными запросами. |
Новый метод модели предметной области
Мы добавляем в модель новый метод, который выполняет изменение количества и освобождение(ий) встроенным и публикует новое событие. Мы также модифицируем существующую функцию выделения для публикации события:
class Product:
...
def change_batch_quantity(self, ref: str, qty: int):
batch = next(b for b in self.batches if b.reference == ref)
batch._purchased_quantity = qty
while batch.available_quantity < 0:
line = batch.deallocate_one()
self.events.append(
events.AllocationRequired(line.orderid, line.sku, line.qty)
)
...
class Batch:
...
def deallocate_one(self) -> OrderLine:
return self._allocations.pop()
Подключаем наш новый обработчик:
HANDLERS = {
events.BatchCreated: [handlers.add_batch],
events.BatchQuantityChanged: [handlers.change_batch_quantity],
events.AllocationRequired: [handlers.allocate],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
И наше новое требование полностью выполнено.
Опционально: Модульное тестирование Event Handlers изолированно с Fake Message Bus
Наш основной тест для рабочего процесса перераспределения-это edge-to-edge (см. Пример кода в [test-driving-ch9]). Он использует реальную шину сообщений и тестирует весь поток, где обработчик событий BatchQuantityChanged запускает освобождение и выдает новые события AllocationRequired, которые, в свою очередь, обрабатываются их собственными обработчиками. Один тест охватывает цепочку из нескольких событий и обработчиков.
В зависимости от сложности цепочки событий вы можете решить, что хотите протестировать некоторые обработчики отдельно друг от друга. Вы можете сделать это с помощью "поддельной" шины сообщений.
В нашем случае мы фактически вмешиваемся, изменяя метод publish_events() в FakeUnitOfWork и отделяя его от реальной шины сообщений, вместо этого заставляя его записывать события, которые он видит:
class FakeUnitOfWorkWithFakeMessageBus(FakeUnitOfWork):
def __init__(self):
super().__init__()
self.events_published = [] # type: List[events.Event]
def publish_events(self):
for product in self.products.seen:
while product.events:
self.events_published.append(product.events.pop(0))
Теперь, когда мы вызываем messagebus.handle() используя FakeUnitOfWorkWithFakeMessageBus, он запускает только обработчик этого события. Таким образом, мы можем написать более изолированный модульный тест: вместо проверки всех побочных эффектов мы просто проверяем, что BatchQuantityChanged приводит к AllocationRequired, если количество падает ниже уже выделенного общего количества:
def test_reallocates_if_necessary_isolated():
uow = FakeUnitOfWorkWithFakeMessageBus()
# test setup as before
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# assert on new events emitted rather than downstream side-effects
[reallocation_event] = uow.events_published
assert isinstance(reallocation_event, events.AllocationRequired)
assert reallocation_event.orderid in {'order1', 'order2'}
assert reallocation_event.sku == 'INDIFFERENT-TABLE'
Хотите вы этого или нет, зависит от сложности вашей цепочки событий. Мы говорим: начните с сквозного тестирования и прибегайте к нему только в случае необходимости.
Подведём итоги
Давайте оглянемся на то, чего мы достигли, и подумаем, "А нафига?".
Чего мы достигли?
События (Events) - это простые классы данных, которые определяют структуры данных для входных данных. и внутренние сообщения в нашей системе. Это довольно мощно с точки зрения DDD, поскольку события часто очень хорошо переводятся на деловой язык (look up event storming if you haven’t already).
Обработчики (Handlers) - это то, как мы реагируем на события. Они могут обратиться к нашей модели или обратиться к внешним службам. Мы можем определить несколько обработчиков для одного события, если захотим. Обработчики также могут вызывать другие события. Это позволяет нам быть очень детальными в отношении того, что делает обработчик, и действительно придерживаться SRP.
Почему мы достигли цели?
Наша основная цель в отношении этих структурных моделей заключается в том, чтобы сложность нашего приложения росла медленнее, чем его размер. Когда мы идем ва-банк на шине сообщений, то как всегда, платим цену с точки зрения архитектурной сложности (См. [chapter_09_all_messagebus_tradeoffs]), но мы приобретаем себе паттерн, который может обрабатывать сколь угодно сложные требования, не нуждаясь в дальнейших концептуальных или архитектурных изменениях в том, как мы делаем вещи.
Здесь мы добавили довольно сложный вариант использования (изменить количество, освободить место, начать новую транзакцию, перераспределить место, опубликовать внешнее уведомление), но в архитектурном плане сложность не требует затрат. Мы добавили новые события, новые обработчики и новый внешний адаптер (для электронной почты), все из которых являются существующими категориями объектов в нашей архитектуре, которые понятны нам и это легко объяснимы новичкам. Каждая из наших подвижных частей выполняет одну задачу, они четко связаны друг с другом, и нет никаких неожиданных побочных эффектов.
| Плюсы | Минусы |
|---|---|
|
|
Теперь вам может быть интересно, откуда берутся эти события BatchQuantityChanged? Ответ станет понятен через пару глав. Но сначала давайте поговорим о событиях в сравнении с командами events versus commands.



Комментарии
Отправить комментарий