7.Агрегаты и границы консистентности
Агрегаты и границы консистентности
В этой главе мы бы хотели вернуться к нашей доменной модели, чтобы поговорить об инвариантах и ограничениях, а также посмотреть, как наши доменные объекты могут поддерживать свою собственную внутреннюю согласованность, как концептуально, так и в постоянном хранении. Мы обсудим концепцию границ консистентности и покажем, как ее постановка может помочь нам построить высокопроизводительное программное обеспечение без ущерба для удобства обслуживания.
[maps_chapter_06] показывает предварительный образ того, куда мы движемся: мы введем новый объект модели под названием Product для упаковки нескольких пакетов batches, и вместо этого сделаем старую доменную службу allocate() доступной в качестве метода в Product.
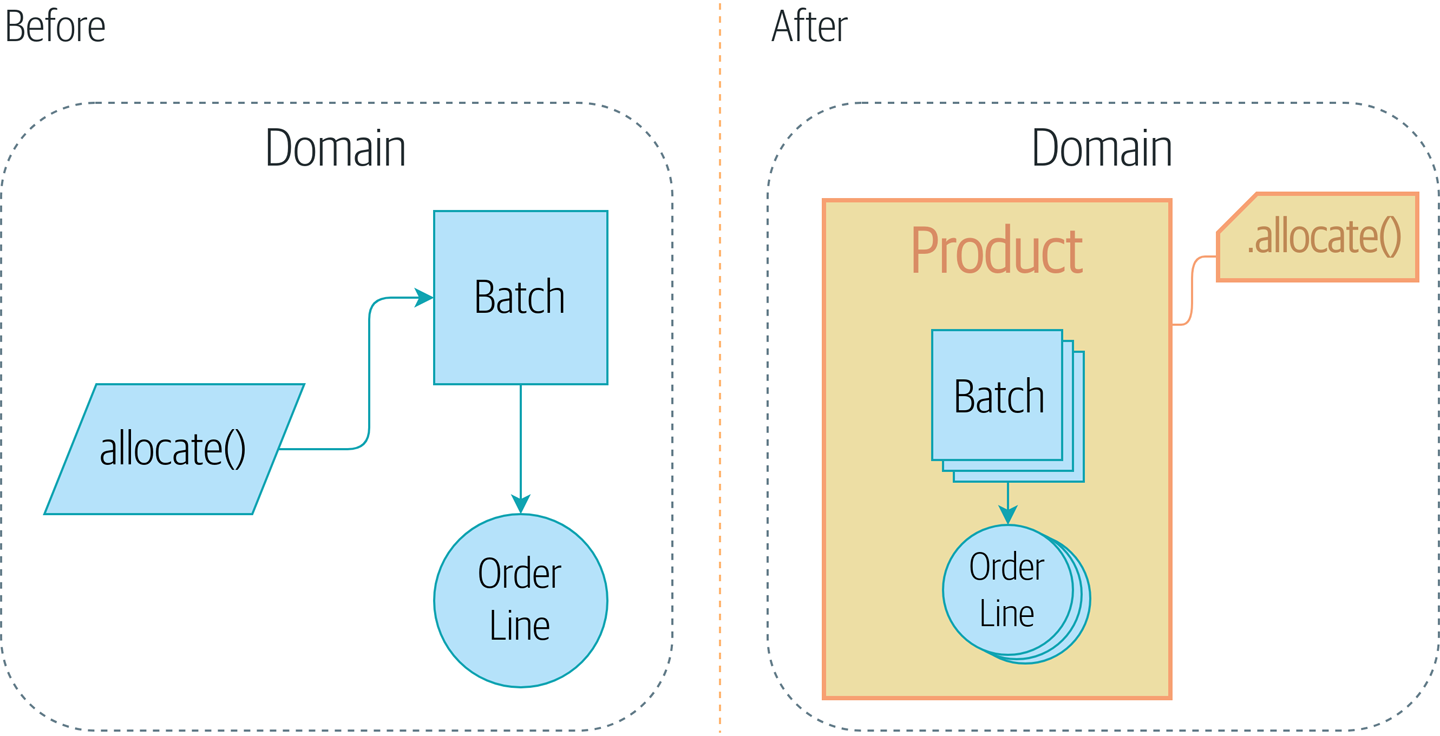
Почему? Давай выясним.
Код этой главы находится в ветке chapter_07_aggregate on GitHub: |
Почему бы просто не запустить все в электронной таблице?
В любом случае, в чем смысл доменной модели? Какую фундаментальную проблему мы пытаемся решить?
Не могли бы мы просто запустить все в электронную таблицу? Многие из наших пользователей были бы в восторге от этого. Бизнес-пользователи любят электронные таблицы, потому что они простые, привычные и в то же время невероятно мощные.
На самом деле, огромное количество бизнес-процессов работают путем ручной отправки электронных таблиц туда и обратно по электронной почте. Эта архитектура «CSV поверх SMTP» имеет низкую начальную сложность, но имеет тенденцию не очень хорошо масштабироваться, потому что трудно применять логику и поддерживать согласованность.
Кому разрешено просматривать это конкретное поле? Кому разрешено обновлять? Что происходит, когда мы пытаемся заказать -350 стульев, или 10 000 000 столов? Может ли работник иметь отрицательную зарплату?
Это ограничения системы. Большая часть логики предметной области, которую мы пишем, существует для обеспечения соблюдения этих ограничений, чтобы поддерживать инварианты системы. Инварианты — это то, что должно быть истинным всякий раз, когда мы заканчиваем операцию.
Инварианты, Ограничения и Консистентность
Эти два слова в некоторой степени взаимозаменяемы, но constraint Ограничения — это правило, ограничивающее возможные состояния, в которые может попасть наша модель, в то время как invariant определяется немного более точно как условие, которое всегда истинно.
Если бы мы писали систему бронирования отелей, у нас могло бы возникнуть ограничение, что двойное бронирование не допускается. Это подтверждает инвариант, что номер не может быть забронирован более чем на одну ночь.
Конечно, иногда нам может понадобиться временно нарушить правила. Возможно, нам нужно перетасовать номера из-за VIP-бронирования. Пока мы перемещаем заказы в памяти, мы можем быть дважды забронированы, но наша модель предметной области должна гарантировать, что, когда мы закончим, мы окажемся в конечном согласованном состоянии, где инварианты будут выполнены. Если мы не можем найти способ разместить всех наших гостей, мы должны поднять ошибку и отказаться от завершения операции.
Давайте рассмотрим несколько конкретных примеров из наших бизнес-требований; мы начнем с этого:
Строка заказа может быть выделена только для одной партии одновременно.
Это бизнес - правило, которое накладывает инвариант. Инвариант заключается в том, что строка заказа распределяется либо на ноль, либо на одну партию, но никогда не более чем на одну. Нам нужно убедиться, что наш код никогда случайно не вызывает Batch.allocate() в двух разных пакетах для одной и той же строки, и в настоящее время ничто явно не мешает нам это сделать.
Инварианты, Параллельность, и Блокировки locks
Давайте рассмотрим еще одно из наших бизнес-правил:
Мы не можем выделить партию, если доступное количество меньше количества строки заказа.
Ограничением здесь является то, что мы не можем выделить больше запасов, чем имеется в наличии для партии, поэтому мы никогда не перепродаем запасы, например, выделяя двух клиентов на одну и ту же физическую подушку. Каждый раз, когда мы обновляем состояние системы, наш код должен гарантировать, что мы не сломаем инвариант, а именно, что доступное количество должно быть больше или равно нулю.
В однопоточном, однопользовательском приложении нам относительно легко поддерживать этот инвариант. Мы можем просто выделить запас по одной строке за раз и вызвать ошибку, если запаса нет.
Это становится намного сложнее, когда мы вводим идею concurrency. Внезапно мы можем распределять запасы для нескольких строк заказа одновременно. Мы могли бы даже выделять строки заказа одновременно с обработкой изменений в пакетах сами для себя.
Обычно мы решаем эту проблему, применяя блокировку locks к нашим таблицам базы данных. Это предотвращает одновременное выполнение двух операций в одной строке или одной таблице.
Когда мы начинаем думать о масштабировании нашего приложения, мы понимаем, что наша модель распределения строк по всем доступным пакетам может не масштабироваться. Если мы обрабатываем десятки тысяч заказов в час и сотни тысяч строк заказов, мы не можем держать блокировку над всей таблицей batches партии для каждого из них — мы получим тупики или проблемы с производительностью, по крайней мере.
Что такое Агрегат?
Итак, если мы не можем блокировать всю базу данных каждый раз, когда хотим выделить строку заказа, что мы должны делать вместо этого? Мы хотим защитить инварианты нашей системы, но при этом обеспечить максимальную степень параллелизма. Сохранение наших инвариантов неизбежно означает предотвращение одновременной записи; если несколько пользователей могут выделить "DEADLY-SPOON" одновременно, мы рискуем перераспределить ее.
С другой стороны, нет причин, по которым мы не можем выделить DEADLY-SPOON одновременно с FLIMSY-DESK. Безопасно выделять два продукта одновременно, потому что нет инварианта, покрывающего оба. Нам не нужно, чтобы они были консистентны друг другу.
Шаблон Aggregate является шаблоном дизайна от сообщества DDD, который помогает нам решить эту проблему. aggregate - это просто объект домена, который содержит другие объекты домена и позволяет нам рассматривать всю коллекцию как единое целое.
Единственный способ модифицировать объекты внутри агрегата - это загрузить его целиком, а также вызвать методы внутри самомого агрегата.
По мере усложнения модели и увеличения числа объектов сущностей и значений, ссылающихся друг на друга в запутанном графе, становится трудно отслеживать, кто и что может изменять. Особенно когда у нас есть collections в модели, как у нас это принято (наши пакеты-это коллекция), это хорошая идея назначить некоторые сущности в качестве единственной точки входа для изменения связанных с ними объектов. Это делает систему концептуально проще и легче обоснуемой, если вы назначаете некоторые объекты ответственными за консистентность над другими.
Например, если мы создаем Интернет-магазин, Корзина может стать хорошим Агрегатом: это коллекция предметов, которые мы можем рассматривать как единое целое. Важно отметить, что мы хотим загрузить всю корзину как одну большую каплю из нашего хранилища данных. Мы не хотим, чтобы два запроса изменяли корзину одновременно, иначе мы рискуем получить странные ошибки параллелизма. Вместо этого мы хотим, чтобы каждое изменение корзины выполнялось в одной транзакции базы данных.
Мы не хотим изменять несколько корзин в транзакции, потому что нет смысла менять корзины нескольких клиентов одновременно. Каждая корзина представляет собой единственную границу соответствия, отвечающую за поддержание своих собственных инвариантов.
АГРЕГАТ - это кластер связанных объектов, который мы рассматриваем как единое целое с целью изменения данных.
— Eric Evans
Согласно Эвансу, наш агрегат имеет корневую сущность (корзину), которая инкапсулирует доступ к элементам. Каждый товар имеет свою индивидуальность, но другие части системы всегда будут относиться к Корзине только как к неделимому целому.
Точно так же, как мы иногда используем _leading_underscores для обозначения методов или функций как "частных", вы можете думать о агрегатах как о "публичных" классах нашей модели, а об остальных сущностях и объектах значений как о "частных"." |
Выбор агрегата
Какой агрегат мы должны использовать для нашей системы? Выбор несколько произвольный, но он важен. Агрегат будет границей, где мы будем следить за тем, чтобы каждая операция заканчивалась в последовательном состоянии. Это помогает нам рассуждать о нашем программном обеспечении и предотвращать тайные расовые проблемы. Мы хотим нарисовать границу вокруг небольшого количества объектов - чем меньше, тем лучше, для производительности - которые должны быть совместимы друг с другом, и мы должны дать этой границе хорошее имя.
Объект, которым мы манипулируем под капотом, - это Batch.. Что мы называем коллекцией партий? Как нам разделить все партии в системе на дискретные острова консистентности?
Мы можем использовать Shipment отгрузку в качестве границы. Каждая отгрузка содержит несколько партий, и все они отправляются на наш склад одновременно. Или, возможно, мы могли бы использовать Warehouse "Склад" в качестве нашей границы: каждый склад содержит много партий, и подсчет всех запасов одновременно может иметь смысл.
Но ни одна из этих концепций нас не удовлетворяет. Мы должны быть в состоянии выделить DEADLLY-SPOONs и FLIMSY-DESK одновременно, даже если они находятся на одном и том же складе или в одной и той же отгрузке. Эти понятия имеют неправильную гранулярность.
Когда мы выделяем линию заказа, нас интересуют только те партии, которые имеют тот же SKU, что и линия заказа. Может сработать какая-нибудь концепция вроде GlobalSkuStock: сбор всех партий для данного SKU.
Однако, это громоздкое имя, поэтому после некоторого пролива велосипедов через SkuStock, Stock, ProductStock и так далее, мы решили просто назвать его Product — в конце концов, это была первая концепция, с которой мы столкнулись при изучении языка домена еще в [chapter_01_domain_model].
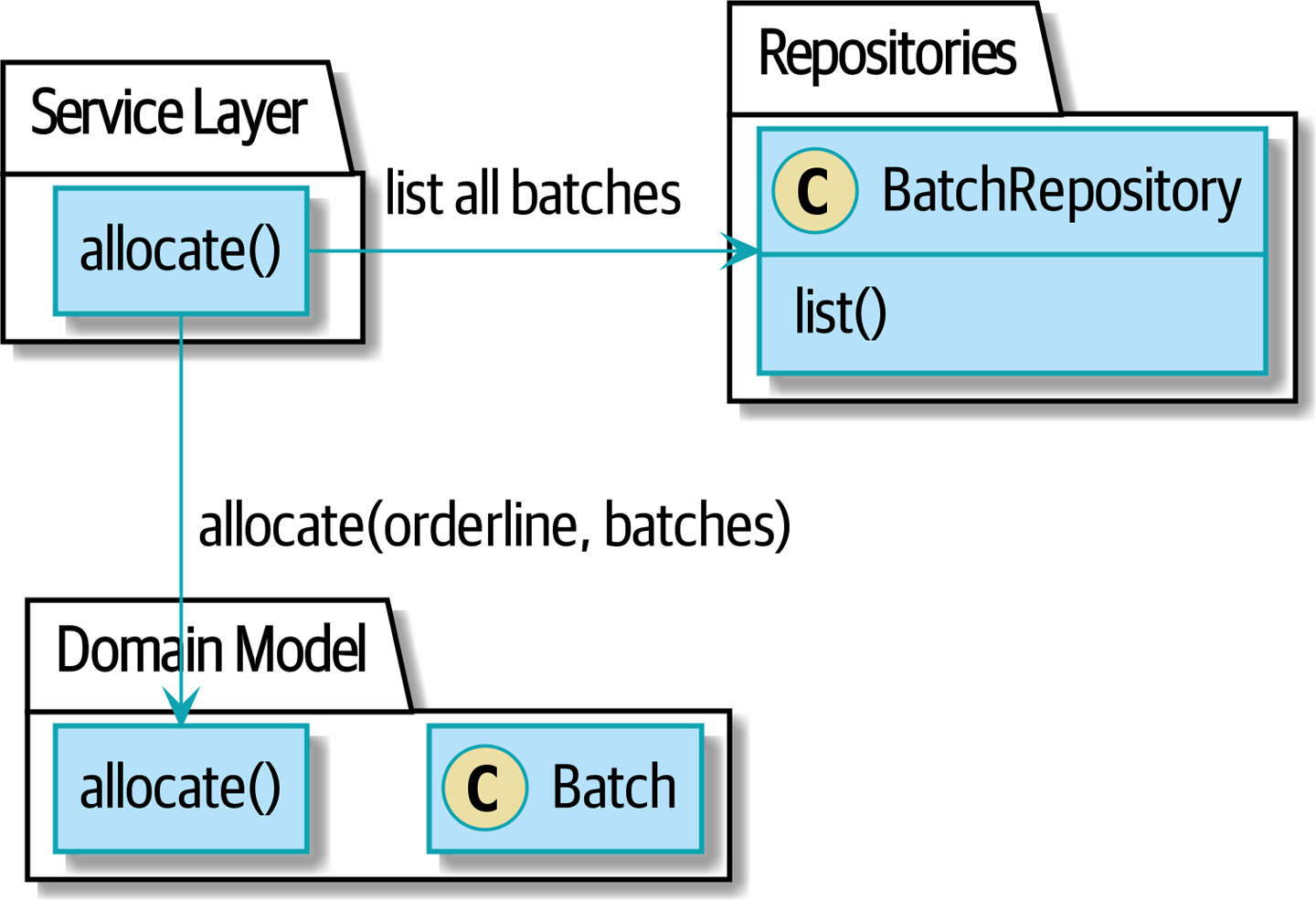
Итак, план таков: когда мы хотим выделить строку заказа вместо [before_aggregates_diagram], где мы ищем все объекты Batch в мире и передаем их службе домена allocate().. .
… мы переместимся в мир [after_aggregates_diagram], в котором есть новый объект Product для конкретного SKU нашей строки заказа который теперь будет отвечать за все партии для этого SKU, и вместо этого мы можем вызвать метод .allocate().
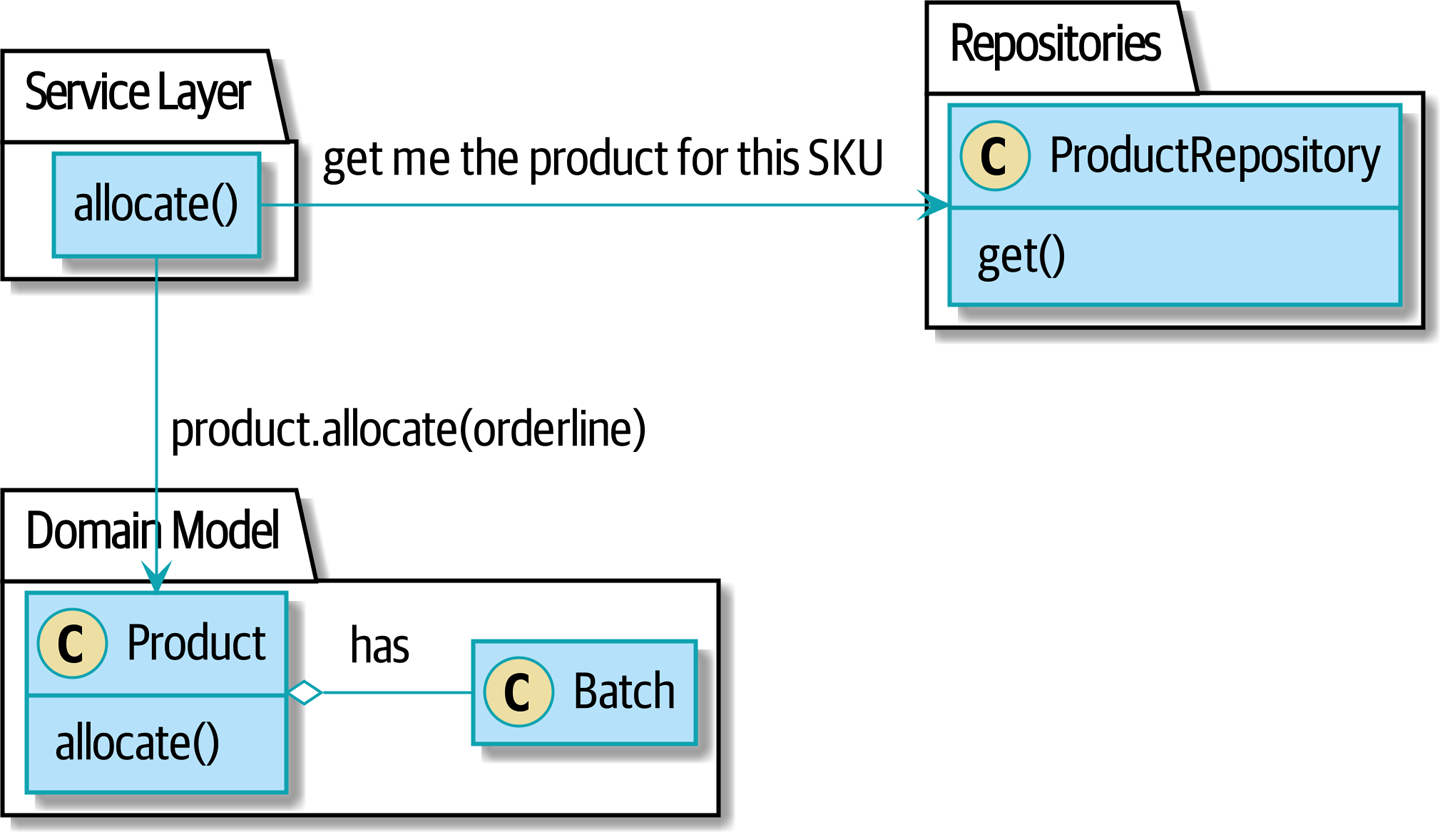
Посмотрим, как это выглядит в виде кода:
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku # self.batches = batches #
self.batches = batches # def allocate(self, line: OrderLine) -> str: #
def allocate(self, line: OrderLine) -> str: # try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')
Основной идентификатор Product - это sku. | |
Наш класс Product содержит ссылку на коллекцию batches для этого SKU. | |
Наконец, мы можем переместить доменную службу allocate() в метод агрегата 'Product`. |
Этот Product может выглядеть не так, как вы ожидаете от модели Product. Ни цены, ни описания, ни габаритов. Нашу службу размещения не волнует ни одна из этих вещей. В этом сила ограниченных контекстов; концепция продукта в одном приложении может сильно отличаться от другого. См. Дополнительную информацию на следующей боковой панели. |
Один Агрегат = Один Репозиторий
Как только вы определяете определенные сущности как агрегаты, мы должны применить правило, что они являются единственными сущностями, которые являются общедоступными для внешнего мира. Другими словами, единственными репозиториями, которые нам разрешены, должны быть репозитории, возвращающие агрегаты.
| The rule that repositories should only return aggregates is the main place where we enforce the convention that aggregates are the only way into our domain model. Be wary of breaking it! |
In our case, we’ll switch from BatchRepository to ProductRepository:
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
def add(self, product):
...
@abc.abstractmethod
def get(self, sku) -> model.Product:
...
The ORM layer will need some tweaks so that the right batches automatically get loaded and associated with Product objects. The nice thing is, the Repository pattern means we don’t have to worry about that yet. We can just use our FakeRepository and then feed through the new model into our service layer to see how it looks with Product as its main entrypoint:
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchref
What About Performance?
We’ve mentioned a few times that we’re modeling with aggregates because we want to have high-performance software, but here we are loading all the batches when we only need one. You might expect that to be inefficient, but there are a few reasons why we’re comfortable here.
First, we’re purposefully modeling our data so that we can make a single query to the database to read, and a single update to persist our changes. This tends to perform much better than systems that issue lots of ad hoc queries. In systems that don’t model this way, we often find that transactions slowly get longer and more complex as the software evolves.
Second, our data structures are minimal and comprise a few strings and integers per row. We can easily load tens or even hundreds of batches in a few milliseconds.
Third, we expect to have only 20 or so batches of each product at a time. Once a batch is used up, we can discount it from our calculations. This means that the amount of data we’re fetching shouldn’t get out of control over time.
If we did expect to have thousands of active batches for a product, we’d have a couple of options. For one, we could use lazy-loading for the batches in a product. From the perspective of our code, nothing would change, but in the background, SQLAlchemy would page through data for us. This would lead to more requests, each fetching a smaller number of rows. Because we need to find only a single batch with enough capacity for our order, this might work pretty well.
If all else failed, we’d just look for a different aggregate. Maybe we could split up batches by region or by warehouse. Maybe we could redesign our data access strategy around the shipment concept. The Aggregate pattern is designed to help manage some technical constraints around consistency and performance. There isn’t one correct aggregate, and we should feel comfortable changing our minds if we find our boundaries are causing performance woes.
Optimistic Concurrency with Version Numbers
We have our new aggregate, so we’ve solved the conceptual problem of choosing an object to be in charge of consistency boundaries. Let’s now spend a little time talking about how to enforce data integrity at the database level.
| This section has a lot of implementation details; for example, some of it is Postgres-specific. But more generally, we’re showing one way of managing concurrency issues, but it is just one approach. Real requirements in this area vary a lot from project to project. You shouldn’t expect to be able to copy and paste code from here into production. |
We don’t want to hold a lock over the entire batches table, but how will we implement holding a lock over just the rows for a particular SKU?
One answer is to have a single attribute on the Product model that acts as a marker for the whole state change being complete and to use it as the single resource that concurrent workers can fight over. If two transactions read the state of the world for batches at the same time, and both want to update the allocations tables, we force both to also try to update the version_number in the products table, in such a way that only one of them can win and the world stays consistent.
[version_numbers_sequence_diagram] illustrates two concurrent transactions doing their read operations at the same time, so they see a Product with, for example, version=3. They both call Product.allocate() in order to modify a state. But we set up our database integrity rules such that only one of them is allowed to commit the new Product with version=4, and the other update is rejected.
Version numbers are just one way to implement optimistic locking. You could achieve the same thing by setting the Postgres transaction isolation level to SERIALIZABLE, but that often comes at a severe performance cost. Version numbers also make implicit concepts explicit. |
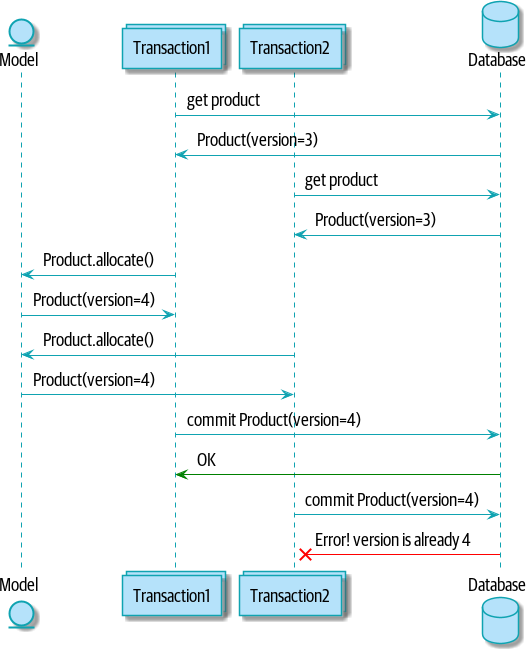
ProductImplementation Options for Version Numbers
There are essentially three options for implementing version numbers:
version_numberlives in the domain; we add it to theProductconstructor, andProduct.allocate()is responsible for incrementing it.The service layer could do it! The version number isn’t strictly a domain concern, so instead our service layer could assume that the current version number is attached to
Productby the repository, and the service layer will increment it before it does thecommit().Since it’s arguably an infrastructure concern, the UoW and repository could do it by magic. The repository has access to version numbers for any products it retrieves, and when the UoW does a commit, it can increment the version number for any products it knows about, assuming them to have changed.
Option 3 isn’t ideal, because there’s no real way of doing it without having to assume that all products have changed, so we’ll be incrementing version numbers when we don’t have to.[1]
Option 2 involves mixing the responsibility for mutating state between the service layer and the domain layer, so it’s a little messy as well.
So in the end, even though version numbers don’t have to be a domain concern, you might decide the cleanest trade-off is to put them in the domain:
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0): #
self.sku = sku
self.batches = batches
self.version_number = version_number #
def allocate(self, line: OrderLine) -> str:
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
self.version_number += 1 #
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')
| There it is! |
If you’re scratching your head at this version number business, it might help to remember that the number isn’t important. What’s important is that the Product database row is modified whenever we make a change to the Product aggregate. The version number is a simple, human-comprehensible way to model a thing that changes on every write, but it could equally be a random UUID every time. |
Testing for Our Data Integrity Rules
Now to make sure we can get the behavior we want: if we have two concurrent attempts to do allocation against the same Product, one of them should fail, because they can’t both update the version number.
First, let’s simulate a "slow" transaction using a function that does allocation and then does an explicit sleep:[2]
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)
Then we have our test invoke this slow allocation twice, concurrently, using threads:
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) #
thread2 = threading.Thread(target=try_to_allocate_order2) #
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 #
[exception] = exceptions
assert 'could not serialize access due to concurrent update' in str(exception) #
orders = list(session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
))
assert len(orders) == 1 # with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute('select 1')
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute('select 1')
We start two threads that will reliably produce the concurrency behavior we want: read1, read2, write1, write2. | |
| We assert that the version number has been incremented only once. | |
| We can also check on the specific exception if we like. | |
| And we double-check that only one allocation has gotten through. |
Enforcing Concurrency Rules by Using Database Transaction Isolation Levels
To get the test to pass as it is, we can set the transaction isolation level on our session:
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
))
| Transaction isolation levels are tricky stuff, so it’s worth spending time understanding the Postgres documentation.[3] |
Pessimistic Concurrency Control Example: SELECT FOR UPDATE
There are multiple ways to approach this, but we’ll show one. SELECT FOR UPDATE produces different behavior; two concurrent transactions will not be allowed to do a read on the same rows at the same time:
SELECT FOR UPDATE is a way of picking a row or rows to use as a lock (although those rows don’t have to be the ones you update). If two transactions both try to SELECT FOR UPDATE a row at the same time, one will win, and the other will wait until the lock is released. So this is an example of pessimistic concurrency control.
Here’s how you can use the SQLAlchemy DSL to specify FOR UPDATE at query time:
def get(self, sku):
return self.session.query(model.Product) \
.filter_by(sku=sku) \
.with_for_update() \
.first()
This will have the effect of changing the concurrency pattern from
read1, read2, write1, write2(fail)to
read1, write1, read2, write2(succeed)Some people refer to this as the "read-modify-write" failure mode. Read "PostgreSQL Anti-Patterns: Read-Modify-Write Cycles" for a good overview.
We don’t really have time to discuss all the trade-offs between REPEATABLE READ and SELECT FOR UPDATE, or optimistic versus pessimistic locking in general. But if you have a test like the one we’ve shown, you can specify the behavior you want and see how it changes. You can also use the test as a basis for performing some performance experiments.
Wrap-Up
Specific choices around concurrency control vary a lot based on business circumstances and storage technology choices, but we’d like to bring this chapter back to the conceptual idea of an aggregate: we explicitly model an object as being the main entrypoint to some subset of our model, and as being in charge of enforcing the invariants and business rules that apply across all of those objects.
Choosing the right aggregate is key, and it’s a decision you may revisit over time. You can read more about it in multiple DDD books. We also recommend these three online papers on effective aggregate design by Vaughn Vernon (the "red book" author).
[chapter_07_aggregate_tradoffs] has some thoughts on the trade-offs of implementing the Aggregate pattern.
| Pros | Cons |
|---|---|
|
|
Part I Recap
Do you remember [recap_components_diagram], the diagram we showed at the beginning of [part1] to preview where we were heading?
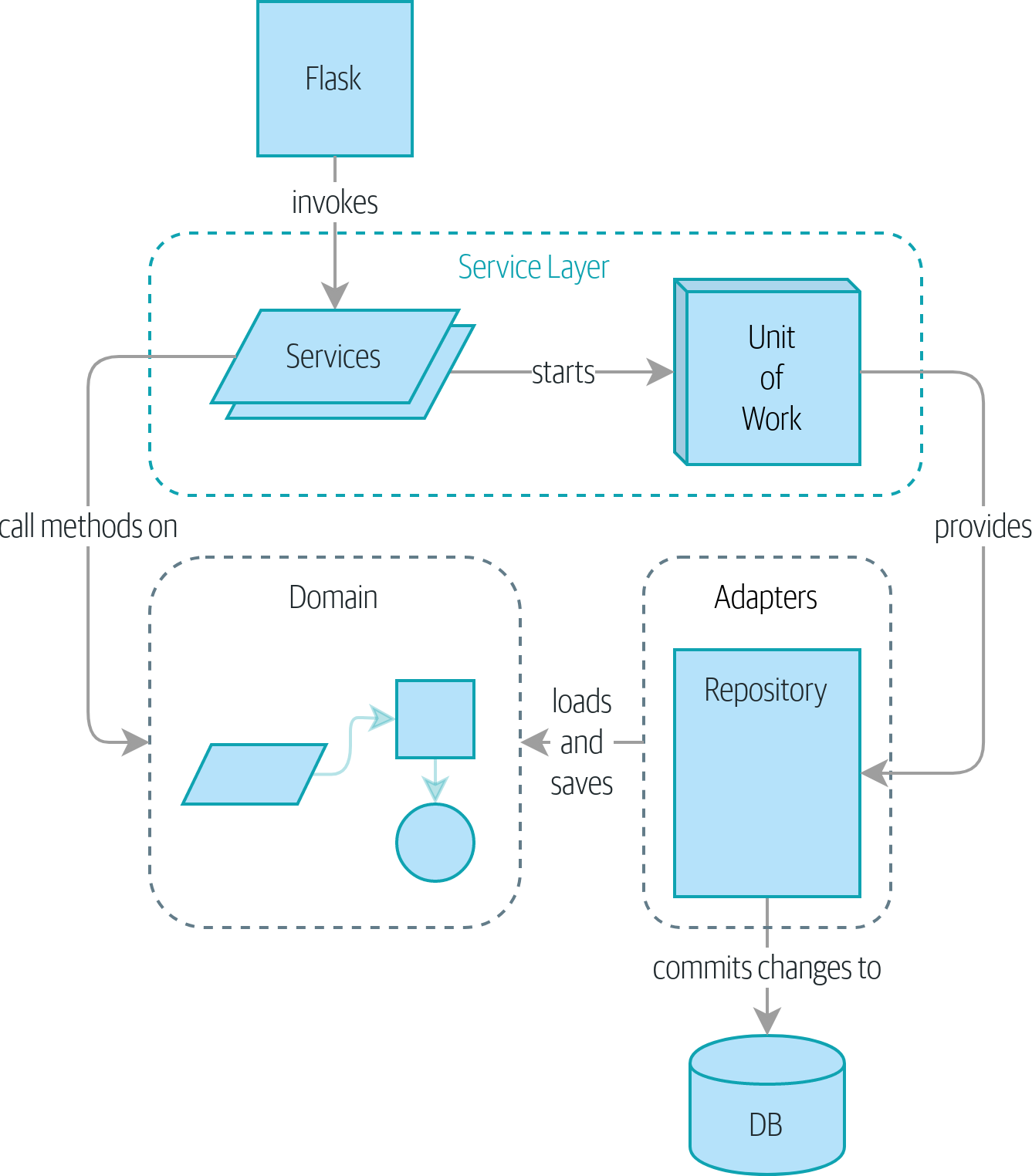
So that’s where we are at the end of Part I. What have we achieved? We’ve seen how to build a domain model that’s exercised by a set of high-level unit tests. Our tests are living documentation: they describe the behavior of our system—the rules upon which we agreed with our business stakeholders—in nice readable code. When our business requirements change, we have confidence that our tests will help us to prove the new functionality, and when new developers join the project, they can read our tests to understand how things work.
We’ve decoupled the infrastructural parts of our system, like the database and API handlers, so that we can plug them into the outside of our application. This helps us to keep our codebase well organized and stops us from building a big ball of mud.
By applying the dependency inversion principle, and by using ports-and-adapters-inspired patterns like Repository and Unit of Work, we’ve made it possible to do TDD in both high gear and low gear and to maintain a healthy test pyramid. We can test our system edge to edge, and the need for integration and end-to-end tests is kept to a minimum.
Lastly, we’ve talked about the idea of consistency boundaries. We don’t want to lock our entire system whenever we make a change, so we have to choose which parts are consistent with one another.
For a small system, this is everything you need to go and play with the ideas of domain-driven design. You now have the tools to build database-agnostic domain models that represent the shared language of your business experts. Hurrah!
| At the risk of laboring the point—we’ve been at pains to point out that each pattern comes at a cost. Each layer of indirection has a price in terms of complexity and duplication in our code and will be confusing to programmers who’ve never seen these patterns before. If your app is essentially a simple CRUD wrapper around a database and isn’t likely to be anything more than that in the foreseeable future, you don’t need these patterns. Go ahead and use Django, and save yourself a lot of bother. |
In Part II, we’ll zoom out and talk about a bigger topic: if aggregates are our boundary, and we can update only one at a time, how do we model processes that cross consistency boundaries?
CsvRepository?time.sleep() works well in our use case, but it’s not the most reliable or efficient way to reproduce concurrency bugs. Consider using semaphores or similar synchronization primitives shared between your threads to get better guarantees of behavior.SERIALIZABLE is equivalent to Postgres’s REPEATABLE READ, for example.


Комментарии
Отправить комментарий